2 Principles of Computer-Based Assessment

Computer-based assessment (CBA) is based on principles and ideas of psychometric measurement and diagnostics Lane, Raymond, and Haladyna (2015), developed in various disciplines, such as psychology, social sciences, and educational research, over many years. Since data collection was done for a long time using paper-based tests and questionnaires, previous research still influences how CBA is designed. However, from the beginning of CBA research, it was anticipated that the change in the technology used for testing, although started with the transfer of existing paper and pencil tests, would also impact the instrument development and the theory of test responses (e.g., Dann, Irvine, and Collis 1991).
Educational Large-Scale Assessments: Beyond the traditions developed for paper and pencil instruments, in particular the implementation of current educational assessments are also influenced by the testing industry (e.g., Bridgeman 2009) and international large-scale assessment (ILSA) programs such as PIAAC (Programme for the International Assessment of Adult Competencies, e.g., Kirsch and Lennon 2017), PISA (Programme for International Student Assessment, e.g., Naumann and Sälzer 2017), TIMSS (Trends in International Mathematics and Science Study, e.g., Fishbein et al. 2018), ICILS (International Computer and Information Literacy Study, e.g., Ihme et al. 2017). These ILSA’s, as well as many national assessment programs such as, for instance, NAEP (National Assessment of Educational Progress, e.g., Bennett et al. 2008) in the U.S. and NEPS (National Educational Panel Study, e.g., Kroehne and Martens 2011) in Germany, have changed from paper-based to computer-based assessment in the past year(s).
Assessment of and for Learning: CBA can be used for summative and formative assessment (e.g., Tomasik, Berger, and Moser 2018) and, when combined with feedback (see section 2.9), is also helpful for self-assessments. It thus goes beyond assessments of learning and can also be used in assessments for learning (Wiliam 2011).
Testing on the Internet: Computer-based assessment, of course, does not only occur within large-scale educational assessments. Instead, cognitive and non-cognitive instruments in various disciplines of the social and behavioral sciences are administered computer-based, online via the internet, or with the help of mobile devices in research and application. While from a technical perspective, different frameworks for creating (native) user interfaces exist for the various platforms, HTML5/JavaScript has emerged as a universally available concept. So, although there are also specific requirements for each of the different delivery formats (see chapter 7) in the context of assessments, a considerable overlap can be observed for the presentation of assessment content in HTML5/JavaScript, in the tradition of what was called psychological testing and assessment on the Internet (e.g., Naglieri et al. 2004).
In the following, advantages of computer-based assessments in comparison to paper-based testing (section 2.1) are described, followed by typical challenges, in particular, with respect to the comparability of assessments using classical response formats (section 2.2). This will be followed by a section on innovative item types (section 2.3), meaning item types there are only available for computer-based assessments. Different forms of item presentation and navigation between items are presented in section 2.4).
2.1 Advantages & Benefits of CBA

Using CBA for the measurement of individual differences or group differences in various personal characteristics such as skills, competencies, personality dimensions, motivation, or attitudes is often motivated by potential benefits that will be briefly mentioned in this section (see, for instance, Haigh 2010).
Standardization: Among the apparent advantages of CBA is that the comparability of assessments can be increased through an increased degree of standardization (e.g., Jurecka 2008). In a computer-based assessment, the item authors can design diagnostic situations, defining which information is visible and accessible at which point (navigation restriction) and how test-takers can interact with the content to answer questions or construct responses. Carefully designed items allow standardizing, for instance, in which sequences tasks can be answered or if questions linked to an audio stimulus are accessible before the audio stimulus was played (navigation restriction). Item authors can also improve the common understanding of response formats by providing animated and interactive tutorial tasks (instructions). Audio and video components might also be used to reduce the reading load of items for all test-takers or as test-accommodation provided for selected test-takers only. Even simple answer formats can be designed in the computer-based assessment in such a way that invalid responses are impossible and test-takers are informed about possible handling errors, e.g. the selection of several answers in a single-choice task.
Scoring: Various additional advantages are achieved by the possibility of instant scoring of closed response formats and selected text responses. (e.g., number inputs or text inputs that can be scored using simple rules like regular expressions and open text responses that can be scored using advanced NLP techniques). Automatically scored information derived from already administered items can be used for various purposes, either during the assessment or to simplify the post-processing of assessment data.
Instant Feedback: During a computer-based assessment, instant feedback is possible on the results, processes and time (see section 2.9.1), the presentation of prompts, and a combination of tasks as scaffolding can improve data quality or implement formative assessment and assessment for learning (i.e., formative assessment). Immediately following the completion of an assessment, result reports can be generated and made available. Feedback can also refer to missing values in the assessment, for instance to reduce accidental overlooking of individual subtasks.
Adaptivity & Measurement Efficiency: If scoring is already available for at least some of the items or questions during the test administration, various forms of adaptivity can be realized. The spectrum of possibilities ranges from hiding particular non-relevant items, simple skip rules, and filters to psychometric approaches such as multi-stage testing and one- or multidimensional adaptive testing as strategies of Automated Test Assembly that can result in an increased Measurement Efficiency (see section 2.7).
Innovative Items / Technology-Enhanced Items (TEI): Computer-based assessment promises to provide benefits for validity and construct representation of assessments using innovative item formats (e.g., Sireci and Zenisky 2015; Wools, Molenaar, and Hopster-den Otter 2019) and technology-enhanced items (TEI, e.g, Bryant 2017), using capabilities provided by the digital environments used for assessment (e.g., Parshall 2002). Item formats that were not possible in paper-based assessment include drag-and-drop response formats, digital hypertext environments (Hahnel et al. 2022), performance-based assessment in simulated environments and authentic assessment (e.g., B. B. Frey, Schmitt, and Allen 2012) to game-based assessments and stealth assessment (e.g., Shute et al. 2016).
Log Data & Process Indicators: Computer-based assessment as a method also provides insight into test processing through behavioral data (Goldhammer and Zehner 2017), i.e., log data (gathered in the form of events) from which process indicators can be derived (Goldhammer et al. 2021). While log data can be collected using technical tools even with paper-based assessments (see, e.g., Dirk et al. 2017; Kroehne, Hahnel, and Goldhammer 2019), the availability and use of log-data from computer-based assessment has developed into a unique area of research (e.g., Zumbo and Hubley 2017).
Response Times: A typical kind of information, which can also be understood as a specific type of process indicator, is the Response Time. Suppose the task design meets specific requirements (e.g., the one item one screen , OIOS, Reips 2010), response times can be easily identified and may already be part of the programming of computer-based assessments. Response times can be used for various purposes, including improving the precision of ability estimates (e.g., Time on Task as used in Reis Costa et al. 2021). However, even when multiple tasks are administered within a unit, time information is available. In that case, item-level response times can either be derived using methods for analyzing log data (Kroehne and Goldhammer 2018), or at least the total time for the entire unit or screen can be derived from computer-based assessments. A specific process indicator that can be derived using response times that allows the identification of disengaged test-taking and careless insufficient responding is Rapid Guessing and Rapid Responding (see section 2.5.3), a thread to validity, in particular, for low-stakes assessments. Response times allow monitoring test-taking engagement and can be used to investigate differences in test-taking motivation (e.g., Kroehne, Gnambs, and Goldhammer 2019).
Online & Mobile Deployment: The manifold possibilities of Internet-based assessment were recognized early on (e.g., Buchanan 2002; Bartram 2005). Since the early years, the possibilities to conduct online assessment under similar conditions have technically improved. For example, it is now possible to carry out assessments in full-screen mode and to register and record exits or interruptions in the log data, if not to prevent them. At the same time, however, the heterogeneity of Internet-enabled devices, tablets, and especially mobile phones has increased. Reliable and secure online and mobile assessments are therefore still a topic of current research and (further) developments.
CBA also results in changed costs for the assessments since the effort to create and test computer-based assessments can be higher (in particular for testing, see section 8.4), but the costs for the distribution of the computer-based administered instruments and the scoring of closed response formats, in particular, can be lower. However, most importantly content created for computer-based assessments can be shared and duplicated without additional costs. While these options obviously do not change the requirements for item protection and confidentiality (see section 2.10), especially concerning assessment content from large-scale assessments, they change how developed assessment instruments from research projects can be distributed and applied in practice (see section 8.7.4). All the potential benefits of CBA come with, for instance, practical challenges (e.g, Mills 2002; Parshall 2002), some of them will be discussed in section 6.
2.2 Standardized Response Formats

The existing standard Question and Test Interoperability (QTI)15 defines simple items with one point of interaction. These simple items can be understood as the standardized form of classical response formats (see Figure 2.1 for an illustration).
Choice Interaction: The QTI Choice Interaction presents a collection of choices to a test-taker. The test-takers response is to select one or more of the choices, up to a maximum of max-choices. The choice interaction is always initialized with no choices selected. The behavior of QTI Choice Interactions regarding the number of selectable choices is described with the attributes max-choices and min-choices.
max-choices and min-choices the CBA ItemBuilder differentiates between RadioButtons (single-choice, see section 3.9.2) and Checkboxes (multiple choice, see section 3.9.3), and the more general concept of FrameSelectGroups (see section 3.5.1).
The QTI standard only differentiates between orientation with the possible values horizontal and vertical, while the CBA ItemBuilder allows you to create any visual layout (including tables) with either RadioButtons and/or Checkboxes (see section 3.5.3).16 Moreover, QTI allows to define the option shuffle to randomize the order of choices.17
(Extended) Text Entry Interaction: The QTI Text Entry Interaction is defined as an inline interaction that obtains a simple piece of text from the test-taker. The delivery engine (i.e., assessment platform) must allow the test-taker to review their choice within the context of the surrounding text. An example illustrating an item from Striewe and Kramer (2018) is shown in Figure 2.1. QTI uses specific so-called class attributes to define the width of text entry component. QTI defines the Extended Text Interaction for tasks where an extended amount of text needs to be entered as the response.
Gap Match Interaction / Associate Interaction / Order Interaction: QTI defines various interactions, that can be realized using drag and drop, such as Gap Match Interaction, Associate Interaction, and Order Interaction (see Figure 2.1). The interactions are defined by QTI for text and graph, depending on the nature of the elements.
Match Interaction: Another interaction that not necessarily needs to be realized using drag and drop is the Match Interaction, that can also be computerized using components of type Checkbox as used for multiple choice responses formats (see Figure 2.1).
HotText / Inline Choice Interaction: For choice interactions embedded in context (e.g. text, image, etc.), the QTI standard defines two different interactions. Two possible implementations, with buttons and ComboBoxes, are shown in Figure 2.1. However, the response formats can also be implemented with other components, for example, Checkboxes (multiple-choice) or RadioButtons (single-choice) for hot text interactions.
Slider Interaction: Response formats in which the possible answers cannot leave a predefined value range contribute to the standardization of assessments. QTI defines such a response format as Slider Interaction (see Figure 2.1).
Additional Interactions Defined by QTI: The QTI standard defines additional interactions not illustrated in Figure 2.1. The Media interaction allows to add audio and video components to items, including a measurement how often the media object was experienced.
Hotspot interaction and Position Object interaction are graphical interactions that allow to select or positions parts of images, while the Drawing interactions describes items in which test-taker can construct graphical responses.
ImageMaps (see section 3.9.10). For more advanced graphical response formats, the CBA ItemBuilder provides the concept of ExternalPageFrames, to embed HTML5/JavaScript content (see section 3.14 and section 6.6 for examples).
QTI also defines the Upload interactions, that is more suited for learning environments and not necessarily for standardized computer-based assessment since uploading material from the computer might violate typical requirements regarding test security (see section 2.10).
PCI Interaction: As shown in Figure 2.1, the CBA ItemBuilder can be used to create items that correspond to the interactions defined by QTI. Figure 2.1 shows a single CBA ItemBuilder task, illustrating two different ways of navigating between interactions. The Innovative Item Types described in section 2.3 below show additional examples beyond the possibilities defined in the QTI standard. To use such innovative items, e.g., tasks created with the CBA ItemBuilder, in QTI-based assessment platforms, QTI describes the Portable Custom Interaction (PCI).
Combination of Interactions: Not all of the interactions standardized by QTI were available in paper-based assessments (PBA) mode. However, in particular, single- and multiple-choice interactions (for closed question types) and text entry interactions (for constructed written responses) were used extensively in PBA, meaning printed and distributed across multiple pages.
Beyond simple items, Items in general are defined by QTI as a set of interactions:19
For the purposes of QTI, an item is a set of interactions (possibly empty) collected together with any supporting material and an optional set of rules for converting the candidate’s response(s) into assessment outcomes.
Distribution of Items on Pages: The QTI standard also provides some guideline how to split content with multiple interactions into items:20
To help determine whether or not a piece of assessment content that comprises multiple interactions should be represented as a single assessmentItem (known as a composite item in QTI) the strength of the relationship between the interactions should be examined. If they can stand alone then they may best be implemented as separate items, perhaps sharing a piece of stimulus material like a picture or a passage of text included as an object. If several interactions are closely related then they may belong in a composite item, but always consider the question of how easy it is for the candidate to keep track of the state of the item when it contains multiple related interactions. If the question requires the user to scroll a window on their computer screen just to see all the interactions then the item may be better re-written as several smaller related items.
Two key points for the computerization of assessments can be derived from the QTI standard:
- The QTI standard defines basic interaction types. However, the combination of multiple items requires either scrolling (if all items are computerized using one page) or paging (i.e., additional interactive elements are required to allow the navigation between items, see section 2.4). The button
View as single page with scrolling ...in Figure 2.1 illustrates the two possibilities.
- The standardization of computerized items goes beyond the definition of individual interactions. For instance, typical QTI items provide a submit button at the end of the page that contains one or multiple interactions (and the submit button is essential to acknowledge, for instance, regarding the precise definition of response times, see section 2.2.2).21
2.2.1 Mode Effects and Test-Equivalence
Items designed for collecting diagnostic information were printed on paper, and simple response formats such as choice interactions and text entry interactions were used that capture the products of test-takers answering items in paper-based assessments. As described in the 2.1 section, there are a number of advantages of computer-based assessment that distinguish this form of measurement from paper-based assessment. Until these advantages are exploited to a large extent and to confirm that existing knowledge about constructs and items holds, research into the comparability of paper- and computer-based assessment is essential (e.g., Bugbee 1996; Clariana and Wallace 2002).
Properties of Test Administration: As described by Kroehne and Martens (2011), different sources of potential mode effects can be distinguished, and a detailed description of properties of test administrations is required, since also different computerization are not necessarily identical. Hence, instead of the comparison between new (CBA) versus old (PBA), the investigation of different properties that are combined in any concrete assessments is required, for instance, to achieve reproducibility.
Item Difficulty and Construct Equivalence: A typical finding for mode effects in large-scale educational assessments is that items become more difficult when answered on a computer (e.g., for PISA, A. Robitzsch et al. 2020). From a conceptual point of view, a separation between the concept of mode effects and Differential Item Functioning (Feskens, Fox, and Zwitser 2019) might be possible, since properties of the test administration can be created by researchers and conditions with different properties can be randomly assigned to test-takers. Consequently, mode effects can be analyzed using random equivalent groups and assessments can be made comparable, even if all items change with respect to their item parameter (Buerger et al. 2019). When advantages available only in computer-based assessment are utilized, the issue of mode effects fades into the background in favor of the issue of construct equivalence (e.g., Buerger, Kroehne, and Goldhammer 2016; Kroehne et al. 2019).
Mode effects might affect not only the response correctness, but also the speed in which test-taker read texts or, more generally, work in computer-based tests (Kroehne, Hahnel, and Goldhammer 2019), and mode effects can also affect rapid guessing (e.g., Kroehne, Deribo, and Goldhammer 2020), and might occur more subtly, for instance, concerning short text responses due to the difference in writing vs. typing (Zehner et al. 2018).
Further research and a systematic review regarding mode effects should cover typing vs. writing (for instance, with respect to capitalization, text production, etc., Jung et al. 2019), different text input methods such as hardware keyboard vs. touch keyboard, different pointing devices such as mouse vs. touch, and scrolling vs. paging (e.g., Haverkamp et al. 2022).
2.2.2 Response Times and Time on Task
Various terms are used in the literature to describe how fast responses are provided to questions, tasks, or items. Dating back to Galton and Spearman (see references in Kyllonen and Zu 2016). Reaction Time measures have a long research tradition in the context of cognitive ability measurement. Prior to the computer-based assessments, response times were either self-reported time measures or time measures taken by proctors or test administrators (e.g., Ebel 1953).
In recent years and in the context of computer-based assessment, Response Time is used to refer to time measures that can be understood as the time difference between the answer selection or answer submission and the onset of the item presentation (see Figure 2.2). However, a clear definition of how response times were operationalized in the computer-based assessments is missing in many publications (e.g., Schnipke and Scrams 1997; Hornke 2005). If log data are used to measure the time, the term Time on Task is used (see, for instance, Goldhammer et al. 2014; Naumann and Goldhammer 2017; Reis Costa et al. 2021).
Extreme Response Times and Idle Times: Response times have a natural lower limit. Short response times faster than expected for serious test-taking can be flagged using time thresholds if necessary (see section 2.5.3). Very long response times occur, for instance, if the test-taking process is (temporarily) interrupted or if the test-taking process takes place outside the assessment platform (in terms of thinking or note-taking on scratch paper). In particular, for unsupervised online test delivery (see section 7.2.1), long response times can also be caused by test-takers exiting the browser window or parallel interactions outside the test system. In order to gather information to allow informed trimming of long response times, it may be useful to record all interactions of test-takers that imply activity (such as mouse movements, keyboard strokes). Log events can then be used to detect idle times that occur when, for whatever reason, the test-taking is interrupted (see section 2.8).
Response Times in Questionnaires: As described in Kroehne et al. (2019) without a precise definition, response times cannot be compared, and alternative operationalizations, for instance, the time difference between subsequent answer changes are possible. In survey research the term Response Latency is used (e.g., Mayerl 2013), both for time measures taking by interviewers or by the assessment software. However, as described by Reips (2010), the interpretation of time measures require to know which task, question or item a test-taker or responded is working on, and additional assumptions are required if test-taker can freely navigate between tasks or see multiple questions per screen. With additional assumptions, item-level response times can, however, be extracted from log data, as illustrated for the example of item-batteries with multiple questions per screen in Figure 2.3.
Time Components from Log Data: Since there are now countless different computer-based tests, many software tools, and assessment implementations, the concept of response times requires a more precise operationalization. One possible definition of time measures uses log events, as suggested as Time on Task. Various response time measures can be extracted from log data using methods developed for log file analyses (see section 2.8). Depending on the item design, all response time measures may require assumptions for interpretation. For example, if items can be visited multiple times, the times must be cumulated over visits. However, this rests on the assumption that the test-taker thinks about answering the task each time a task is visited. If multiple items are presented per screen and questions can be answered in any sequence, an assumption is necessary that each time a test-taker thinks about a question, this will be followed by an answer change.
2.2.3 Time Limits (Restrict Maximum Time)
Traditionally, in paper-based large scale assessments, time limits for tests or booklets were mainly used. Restricting the time for a particular test or booklet has the practical advantage that this type of time limit can also be controlled and implemented in group-based test administrations. A similar procedure can also be implemented in computer-based assessment. A time limit is defined for the processing of several items (e.g., for the complete test or a sub-test or section), and after the time limit has expired, the tasks for a particular test part can no longer be answered.
In contrast, however, computer-based testing also allows the implementation of time limits for individual tasks or small groups of items (e.g., units). The advantage is obvious: While time limits at the test level or booklet level can result for various reasons in large inter-individual differences in the number of visited items (for instance, due to individual test-taking strategies or individual items that a test person is stuck on), time limits at item level can be implemented in such a way that all persons can see each item for at least a certain amount of time. Computer-based assessment allows to differentiate between time limits at the item level and time limits at test level. In between, time limits for item bundles, e.g., units, can be created. If the comparability of psychometric properties of an assessment to an earlier paper-based form is not necessary or if this comparability can be established, for example, on the basis of a linking study, then time limits can be used purposefully in the computer-based assessment to design the data collection. For example, if a test is administered in only one predetermined order (i.e., no booklet design), time limits at the test level will result in not-reached items depending on the item position.
Time limits do not only restrict test-taking. Time limits also give the test-takers feedback on their individual chosen pace of working on the task (e.g., Goldhammer 2015). Different possibilities to give feedback during the assessment are described in section 2.9.1). The item design of Blocked Item Response (see section 2.4.1 can be used to force a minimum time for individual items.
2.3 Innovative Item Types / Technology-Enhanced Items (TEI)

New item formats for computer-based assessment are called Innovative Item Formats (e.g., Sireci and Zenisky 2015; Wools, Molenaar, and Hopster-den Otter 2019) or Technology-Enhanced Items (TEI, e.g, Bryant 2017), and early attempts defined innovative item formats as items using capabilities not available in paper-based assessment (e.g., Parshall 2002). Innovations through computer-based assessment were also described along the dimensions of Complexity (A=less complex to D=more complex) and Constraintness (1=fully selected to 7=fully constructed) (see Figure 2.4 and Figure 1 in Scalise and Gifford 2006).
FIGURE 2.4: Item illustrating different item formats described in (Scalise and Gifford 2006, html|ib).
Since the early attempts to define innovative item formats, research practice has produced many forms of simulation-based, authentic, and interactive assessments in recent years. Examples created with the CBA ItemBuilder include:
- Assessment of ICT literacy with simulations (see, for instance, Fig. 6.2 in Goldhammer and Kroehne 2020)
- Evaluation of online information Hahnel, Jung, and Goldhammer (2023)
- Complex problem solving (see, for instance, Fig 1 in Tóth et al. 2014)
- Technical problem solving (see, for instance, Fig 1 in Stemmann 2016)
- Highlighting as response format (e.g., for PIAAC, Schnitzler et al. 2013; and for the National Educational Panel Study, NEPS, Heyne et al. 2020)
- Multiple Document Literacy (e.g., Fig 1 in Hahnel et al. 2019)
- … (to be continued) …
2.4 Item Presentation and Navigation

The term Navigation (or interface navigation) within assessments refers to the provided possibilities for test-takers to switch back and forth between items. Software tools and assessment platforms provide different interfaces for navigating between Tasks, and as the ICT/ATP Guidelines for Technology-Based Assessment suggest,22 test-takers should be informed about navigating between tasks and have opportunities to practice navigation before the assessments.
Screen Layout: In order to be able to describe the options for navigation within assessments, one must first be aware of how the instructions and items in a computer-based assessment are presented on screen. Either only one item is displayed in full screen (Full Page Items, see section 2.4.1), or one or more additional visual components, for instance, for navigation, progress display, etc., are presented together with the item (Integrated Item Presentation, see section 2.4.6) on screen.
Combining multiple text entries, for instance, in C-tests (see section 2.4.3) or more general as so-called Cloze tests or in an Embedded Answers response format results in screen layout with multiple interactions per page. Text entry response formats (and other response formats as well) typically define one focused element, resulting in a Within-Item Navigation. Combining multiple items, for example, items with a common stimulus can also result in dependencies between assessment items. For this reason, it may be helpful to further distinguish between navigation within related items (referred to as Units, see Within-Unit Navigation in section 2.4.4) and navigation between items (see Between-Unit / Test-Level Navigation in section 2.4.5). Finally, for operational reasons, some assessment components have a unique role. Examples of this are so-called stop items, which are used in group tests to synchronize test processing in terms of time (see section 2.4.2).
Presentation Size: The planned screen layout determines how much space the assessment content can occupy (i.e., the required Size of items on screen). Screen size is usually specified in pixels. In addition, the Resolution (also measured in Pixels) must be distinguished from the actual size of the display, which depends on the physical size of the screens (usually specified in Inches of the diagonal). Finally, for the translation from Pixels (resolution) to Inches (display size), the pixel density as the amount of pixels per inch (often specified as dpi, i.e., dots per inch) and potential zoom factors must be taken into account. Zoom factors can be device-specific (i.e., a magnification implemented, for instance, by the operating system) or in browser-based deliveries also implemented by the web browser.
Aspect Ratio and Screen Orientation: The ratio of the width to the height of a screen is called the aspect ratio, resulting in terms like 4:3 (e.g., screens with a resolution of 1024x768 pixels), 16:9 (e.g., screens with a resolution of 1920x1080 pixels), etc., which are also used to characterize screens. Finally, the aspect ratio also determines the orientation of screens. If the width is larger than the height, one speaks of Landscape Format, if the height is larger than the width of Portrait Mode.
Windows Size and Browser Size: For web-based delivered assessments or other forms of delivery that are not standardized using a kiosk solution, the window size or the size of the browser must also be considered. In the worst case, this can cause the user to change the display size during test processing. On some operating systems, even for web-based deliveries, the browser full-screen mode can at least prevent the window size from changing.
Proportional Scaling: When assessments are not run on uniform hardware, determining the exact Item Size is often tricky in practice. It is even often impossible, especially if the item contents are only displayed embedded (see section 2.4.6) or if the available display area may even change due to the window size. This is countered by the demand to design as precisely as possible what the test-takers see in the context of a standardized assessment at a given time and how they can interact with the item material. One possible solution to this challenge is to implement Proportional Scaling of item content. This uses the available space on the screen while maintaining the aspect ratio until either height or width is exhausted.
Scrolling: An obvious way to display more content on a screen than the screen size allows is to use scrollbars. In fact, in HTML-based implementations of computer-based assessments, these often appear automatically. Vertical scrolling, in particular, should be used with caution for diagnostic reasons (see section 2.2.1). For detailed analyses, it may also be necessary to infer later from the data what a test-taker saw at a point in time (see section 2.8). Finally, it must be considered whether the entire screen or only parts of the display should scroll, for example, if a navigation area is to be permanently displayed on the screen.
Responsive Design: A more typical way for websites to deal with different resolutions and screen sizes is the use of so-called Responsive Designs. In Responsive Designs, the arrangement and display of the content are adapted to the actual available area (View Port). In the context of computer-based assessments, the use of responsive designs must be weighed up against the extent to which this can be reconciled with the goal of standardizing assessments.
2.4.1 Full Page Items
Full Page Items represent an item design in which minimal non-solution interactions with the assessment platform are required. Full Page Items can be implemented without scrolling and with scrolling, as shown in Figure 2.5. The central feature of Full Page Items is that they are presented exclusively on the screen, without being surrounded by a navigation area. Necessary navigation elements are displayed within the item when they should be available.
The design and presentation of items should always clarify whether they are instructional text or a question. In addition, it should be explained (either in the instruction at the beginning of the assessment or through short instructional texts) how the item can be processed and answered. If multiple pages are used, the navigation buttons must be repeated on each page.
Forced Choice: A unique response format in which items are typically displayed without navigation is Forced Choice. In this format, which is also used for questionnaires, the test takers are not offered the option of not answering. As shown in the examples in Figure 2.6, the system automatically navigates to the next question as soon as an answer is given.
Multiple forced choice questions can also be presented on one page and still be administered in a fixed order, as the example in Figure 2.6 shows.
Blocked Item Response In cognitive and non-cognitive assessments, rapid responding (see Rapid Guessing and Rapid Responding in section 2.5.3) is a phenomenon that compromises the validity of responses. A naive way to limit response elicitation is to disable the buttons for a limited time. Example 3 in Figure 2.6 shows this concept in combination with the forced-choice response format, Figure 2.8 shows this concept with other response formats (see also Persic-Beck, Goldhammer, and Kroehne 2022).
2.4.2 Breaks / Stop Items
For different operational reasons, it may be necessary to interrupt and pause the flow of computerized instruments or to insert positions where test-takers should take a break. According to the logic described in this section, these pause pages are Full Page Items, since no further navigation should be possible.
Magic Word: In school assessments, test administration is often organized as on-site group tests with a test administrator present in the room. If the assessment is administrated using secure offline environments (e.g. in a kiosk mode, see 7.2.3), breaks for the group can be easily implemented with a Magic Word (i.e., a piece of information that functions as a password), which is only announced by the test administrator at the time when every test-takers should start with a following section.
Dashboards: Computer-based assessments are also often administered in network environments (e.g., web-based), enabling centralized control across test-takers. So-called Dashboards for test management can show, for example, which task a test-taker is currently working on or whether a test taker needs support. Dashboards can also be used for the control of group testing or for monitoring online test administrations, for instance, by remote interviewers.
2.4.6 Integrated Item Presentation
In various contexts, items are displayed and integrated within other web application or web-based deliveries. This includes, for instance, the integration of CBA ItemBuilder items within QTI-based deployment software (such as TAO) as Portable Custom Interaction (PCI) (see section 7.4), or more general embedding CBA ItemBuilder items using the so-called TaskPlayer-API (see section 7.7). Another possible scenario is the integration of assessments within learning management systems (e.g. Moodle) based on the LTI interface (see section 7.5.8).
In scenarios where assessment components are integrated into other deliveries, the following points need special consideration:
- Presentation Size: The size of the item displayed within other software environments is often smaller than the available space on the screen. Therefore, the items may need to be made smaller so that they can be answered reasonably in the embedded presentation. This can also result in the display of scroll bars on different screen sizes if the web application adjusts the size of the integrated items (responsive design).
- Re-Visits / Restore: The integration of items within external applications may result in items being terminated and re-entered by external navigation. To ensure a coherent picture for the test-takers and that the content shows the last working state on each new visit, the items must save their state before exiting.
- Full Screen: Full-screen presentation control must take into account when items are integrated into other web applications.
Suppose assessment components, which themselves allow inner navigation or should not be terminated at any time, are integrated into other environments (e.g., via PCI in TAO, see section 7.4). In that case, the navigation in the external application must be blocked.
2.5 Scoring and Calibration

Many psychometric CBA applications rest on principles of psychological and educational measurement (see, e.g., Veldkamp and Sluijter 2019) and typical design principles for tasks/items and tests that also apply to non-technology-based assessments are still valid (see, e.g., Downing and Haladyna 2006). For instance, approaches to increase the measurement efficiency use a particular item response theory (IRT) model and (pre-)calibrated item parameters (see also section 2.7):
- Difficulty Parameter or Threshold Parameters,
- Discrimination Parameter (Loading) and
- (Pseudo)Guessing Parameter.
Which item parameters are used to model the probability of a correct response (or a response in a particular category) as a function of a one- or multidimensional latent ability depends on the choice of a concrete IRT model (see, for instance, Embretson and Reise 2013 for a general introduction). Bolt (2016) list the following IRT models for CBA:
- Models for innovative item types (polytomous IRT models and multidimensional IRT models) and models related to testlet-based administration (see section 2.5.1)
- Models that attend to response times (see section 2.5.6)
- Models related to item and test security (see section 2.10.1)
Further areas of application for (IRT) models in the context of CBA include:
- Models to deal with missing values (see section 2.5.2)
- Models to deal with rapid guessing (see section 2.5.3)
- Models for automated item generation (see section 2.6)
Another class of IRT models that is often used with CBA data are Cognitive Diagnostic Models (CDM, see, e.g., George and Robitzsch 2015 for a tutorial)). Additional information, available when data are collected with CBA, such as response times and more general process data (see section 2.8) can be used in cognitive diagnostic modeling (e.g., Jiao, Liao, and Zhan 2019).
2.5.1 Scoring of Items
Computer-based assessment consists of a sequence of assessment components, i.e., instructions and between-screen prompts, and purposefully designed (digital) environments in which diagnostic evidence can be collected. The atomic parts for gathering diagnostic evidence are called items, typically consisting of a prompt (or a question) and the opportunity to provide a response. Items can include introductory text, graphics, tables, or other information required to respond to the prompt, or questions can refer to a shared stimulus (creating a hierarchical structure called units). The raw response provided to items is typically translated into a numerical value called Score.
Dichotomous vs. Polytomous Scoring: For the use of responses to determine a person’s score, a distinction is commonly made between dichotomous (incorrect vs. correct) and polytomous (e.g., no credit, partial credit, full credit). While this distinction is essential, for example, for IRT models, these two kinds are not mutually exclusive concerning the use of information collected in computer-based assessment. Identical responses can be scored differently depending on the intended use. For instance, a polytomous score can be used for ability estimation, while multiple dichotomous indicators for specific potential responses can provide additional insight in formative assessment scenarios.
Multiple Attempts & Answer-Until-Correct: In computer-based assessments, the process of the test-taking and responding can also be included in the scoring. This allows scenarios in which test-takers can answer an item multiple times (e.g., Attali 2011) or until correct (e.g., DiBattista 2013; Slepkov and Godfrey 2019). While this goes beyond the simple IRT models, it can be included in addition to a traditional scoring of the (first) attempt or the final response prior to a provided feedback (see section 2.9).
Constructed Response Scoring: Scores can be calculated automatically for closed response formats (i.e., items that require selecting one or multiple presented response options). For response formats beyond that, scoring can require human raters, pattern recognition (e.g., using Regular Expressions, see section 6.1), or Natural Language Processing (NLP) techniques and machine learning (typically using some human-scored training data, see, for instance, Yan, Rupp, and Foltz 2020).
Scoring of Complex Tasks: Special scoring requirements may arise for complex tasks that consist of multiple subtasks or where multiple behavior-based indicators are derived. Possible approaches for scoring multiple responses include aggregating the total number of correct responses, used, for instance, to score C-tests as shown in Figure 2.9 (see, for instance, Harsch and Hartig 2016 for an example). If (complex) items share a common stimulus or if for any other reason responses to individual items influence each other, dependencies may occur that require psychometric treatment (see, for instance, the Testlet Response Theory in Williamson, and Bejar 2006).
The scoring of answers is, among other things, the basis for automatic procedures of (adaptive) test assembly (see section 2.7) and for various forms of feedback (see section 2.9), among others regarding the completeness of test processing. For this purpose, a differentiated consideration of missing responses is also necessary, as described in the following sub-section.
2.5.2 Missing Values
Scoring can also take the position of items within assessments into account. This is typically done when differentiating between Not Reached items (i.e., responses missing at the end of a typically time-restricted section) versus Omitted responses (i.e., items without response followed by items with responses). Computer-based assessment can be used to further differentiate the Types of Missing Responses, resulting in the following list:
Omitted responses: Questions skipped during the processing of a test lead to missing values typically described as Omitted Responses. How committed responses should be taken into account when estimating item parameters (see section 2.5.4) and estimating person parameters (see section 2.5.5) depends on the so-called missing-data mechanisms (see, for instance, Rose, von Davier, and Nagengast 2017).
Not reached items: If there is only a limited amount of time provided to test-takers to complete items in a particular test section, answers may be missing because the time limit has been reached. These missing responses are called not reached items. The arrangement of the items and the possibilities of navigation within the test section must be considered for the interpretation of missing values as Not Reached.
Quitting: An example that tasks can be incorrectly classified as Not Reached is described in Ulitzsch, von Davier, and Pohl (2020). Missing values at the end of a test section can also indicate that the test was terminated if testing time was still available.
Not administered: Missing responses to items that were not intended for individual test-takers, for instance, based on a booklet design (see section 2.7.2). Since these missing values depend on the test design (see section 2.7.2), they are often referred to as Missing by Design.
Filtered: Items may also be missing because previous responses resulted in the exclusion of a question.
Missing Value Coding: In computerized assessment, there is no reason to wait until after data collection to classify missing responses. Features of interactive test-taking can be considered during testing to distinguish missing responses using the described categories as part of scoring (see chapter 5).
Use of Log-Data for Missing Value Coding: An even more differentiated analysis of missing responses is possible by taking log data into account. The incorporation of response times for the coding of omitted responses (e.g., A. Frey et al. 2018) is one example for the use of information extracted from log data (see section 2.8). Response elements that have a default value require special attention. For instance, checkboxes (see section 3.9.3) used for multiple-choice questions have an interpretation regarding the selection without any interaction (typically de-selected). Log data can be used to differentiate whether an item with multiple (un-selected) checkboxes has been solved or the item should be coded as a missing response.
Missing responses can provide additional information regarding the measured construct, and their occurrence may be related to test-taking strategies. As described in the next section, rapid missing responses may also be part of a more general response process that is informative about test-taking engagement.
2.5.3 Rapid Guessing
Computer-based assessment can make different types of test-taking behaviors visible. A simple differentiation into solution behavior and rapid guessing was found to be beneficial (Schnipke and Scrams 1997), that can be applied, when response times (as discussed in the previous section 2.2.2) are available for each item or when an item design is used that allows interpreting individual time components (see section 2.8.2). Rapid guessing is particularly important for low-stakes assessments Goldhammer, Martens, and Lüdtke (2017).
While solution behavior describes the (intentional) process of deliberate responding, a second process of very fast responding can be observed in many data sets. Since both processes can often be clearly separated when inspecting the response time distribution, a Bimodal has become a central validity argument (see, for instance, Wise 2017) for focusing on Rapid Guessing as a distinguished response process. Using the bimodal response time distribution, a time threshold can be derived, and various methods exist for threshold identification (e.g., Soland, Kuhfeld, and Rios 2021), using either response time and or (in addition to) other information-based criteria (e.g., Wise 2019).
Alternatively to simple time thresholds, mixture modeling (e.g., Schnipke and Scrams 1997; Lu et al. 2019) can be used to differentiate between solution behavior and rapid guessing when post-processing the data. Treatments of rapid responses include response-level or test-taker-level filtering (see Rios et al. 2017, for a comparison). However, similar to missing values (see above), a treatment of responses identified as rapid guessing might require to take the missing mechanism into account (e.g., Deribo, Kroehne, and Goldhammer 2021). Further research is required regarding the operationalization of rapid guessing for complex items (see, e.g., Sahin and Colvin 2020, for a first step in that direction) and validating responses identified as Rapid Guessing (e.g., Ulitzsch, Penk, et al. 2021). Another area of current research is the transfer of response-time-based methods to identify Rapid Guessing to non-cognitive instruments and the exploration of Rapid Responding as part of Careless Insufficient Effort Responding (CIER), either using time thresholds or based on mixture modeling (e.g., Ulitzsch, Pohl, et al. 2021).
2.5.4 Calibration of Items
After constructing a set of new assessment tasks (i.e., single items or units), the items are often administered in a pilot study (often called calibration study). Subsequently, a sub-set of items is selected that measures a (latent) construct of interest in a comparable way, where the selection of items is typically guided in the context of the Item Response Theory (see, e.g., Partchev 2004) regarding Item Fit, and so-called Item Parameters are estimated. Different tools and, for instance, R packages such as TAM (Alexander Robitzsch, Kiefer, and Wu 2022) can be used to estimate item parameters and to compute (item) fit indices.
Missing values can be scored in different ways for item calibration and ability estimation (see Alexander Robitzsch and Lüdtke 2022 for a discussion), depending, for instance, on assumptions regarding the latent missing propensity (see, for instance, Koehler, Pohl, and Carstensen 2014). The treatment of rapid guessing can improve item parameter estimation (e.g., Rios and Soland 2021; Rios 2022).
IRT models exist for dichotomous and polytomous items (see section 2.5.1). When multiple constructs are collected together, multidimensional IRT models can increase measurement efficiency (see, e.g., Kroehne, Goldhammer, and Partchev 2014).
Known item parameters are a prerequisite for increasing measurement efficiency through automatic test assembly and adaptive testing procedures (see section 2.7), and techniques such as the Continuous Calibration Strategy (Fink et al. 2018) can help to create new Item Pools.
Item parameters are only valid as long as the item remains unchanged. This limits the possibilities for customizing items, even if they are shared as Open Educational Resources (OER, see section 8.7.4).
2.5.5 Ability Estimation
While the estimation of item parameters is typically done outside the assessment software as part of test construction, the computation of a raw score (e.g., the number of items solved) or the estimation of a (preliminary) person-ability (using IRT and based on known item parameters) is a prerequisite for the implementation of methods to increase measurement efficiency (multi-stage testing or adaptive testing, see section 2.7). Rapid guessing (see section 2.5.3, e.g., Wise and DeMars 2006) as well as informed guessing can be acknowledged when estimating person parameters (e.g., Sideridis and Alahmadi 2022).
2.5.6 Incorporation of Response Times
A long research tradition deals with the incorporation of response times in psychometric models. Based on the hierarchical modeling of responses and response times (van der Linden 2007) response times can be used, for instance, as collateral information for the estimation of item- and person-parameters (van der Linden, Klein Entink, and Fox 2010). Response times (and more generally, Process Indicators, see section 2.8) used to improve item response theory latent regression models (Reis Costa et al. 2021; Shin, Jewsbury, and van Rijn 2022). In combination with missing responses response-time related information (in terms of not reached items) can also be included in the ability estimation using polytomous scoring (Gorgun and Bulut 2021).
2.6 Automated Item Generation

Automatic item generation (AIG) is used to describe the process of generating items using computer technology, typically using some kind of models (e.g., cognitive models, Gierl, Lai, and Turner 2012). A template-based approach (Gierl and Lai 2013) formulates an item model (also called, for instance, schema or blueprint) containing the components of a task that can be varied to generate items. Item models can be described regarding the number of layers in which item clones (i.e., generated items) differ from a source. While AIG from an IRT perspective, for instance, generating items on the fly was suggested more than ten years ago (e.g., Embretson and Yang 2006), current research incorporating machine learning techniques such as deep learning (e.g., von Davier 2018) and models developed for natural language processing can be expected to provide promising new methods and applications (see for a review, e.g., Das et al. 2021; and for an example Attali et al. 2022).
2.7 (Automated) Test Assembly

When more items are available than can or should be completed by a test-taker, the term Test Assembly is used to describe the psychometric process of combining items to test Booklets or Rotations. The test assembly process usually requires items with known item parameters (see section 2.5.4) and can be performed manually or automatically (van der Linen 2006).
The research literature on automated test composition provides insight into criteria that are considered when assembling tests. The primary criterion is typically provided by item response theory, i.e., the selection of items to optimize the measurement by taking already available information about the anticipated test-takers (for instance, the expected ability distribution) into account.
Constraints: Approaches that formalize the test assembly (e.g., Diao and van der Linden 2011) can also incorporate additional criteria (i.e., constraints for the test assembly when conduced, for instance, in R, see Becker et al. 2021), such as:
- Content: Content areas or domains of requirements, defined as test specification in relation to an underlying assessment framework (i.e., the test blueprint)
- Response Format: Response format or number of response alternatives, or the position of the correct responses
- Item Position: Balancing the position of items or keeping the position of certain items constant (e.g. link items)
- Response Time: Expected time to solve the item (can be used to assemble tests that with comparable time limits)
Constraints can be considered in test composition to make different individual tests comparable or to balance and account for item properties at a sample or population level. Moreover, constraints might also be used to achieve further operational goals, such as the interpretability of adaptive tests at the group level for formative assessment purposes (e.g., Bengs, Kroehne, and Brefeld 2021).
2.7.1 Fixed Form Testing
Assessments with a fixed set of items can be seen as the typical use case for test deployments, either in the preparation of IRT-based applications of tailored testing (i.e., to collect data for item calibrations) or as the final output of test development. As shown in Panel A of Figure 2.14, a fixed form testing requires the administration of assessment components as linear sequence.

FIGURE 2.14: Fixed Form Testing with linear sequence of Tasks
Criteria for item selection, optionally taking into account constraints, is reflected in the selection of Tasks that are included in the linear sequence.
A first differentiation of the structure also of Fixed Form test assemblies (see Panel B in Figure 2.14) concerns the distinction in assessment components which are administered BEFORE the actual tasks (Prologue), the tasks themselves (Main), and the assessment components which are administered AFTER the main tasks (Epilogue). The subdivision made can be helpful if, for example, a time limit is required for a part of the assessment components (Main),25 but the time measurement does not begin until the instruction is completed (Prologue) and a uniform test-taker enactment is to be implemented (Epilogue).
Test designs using Fixed Form Testing can also incorporate multiple tests, domains or groups of Tasks as shown in Figure 2.15, by repeating multiple Test Blocks.
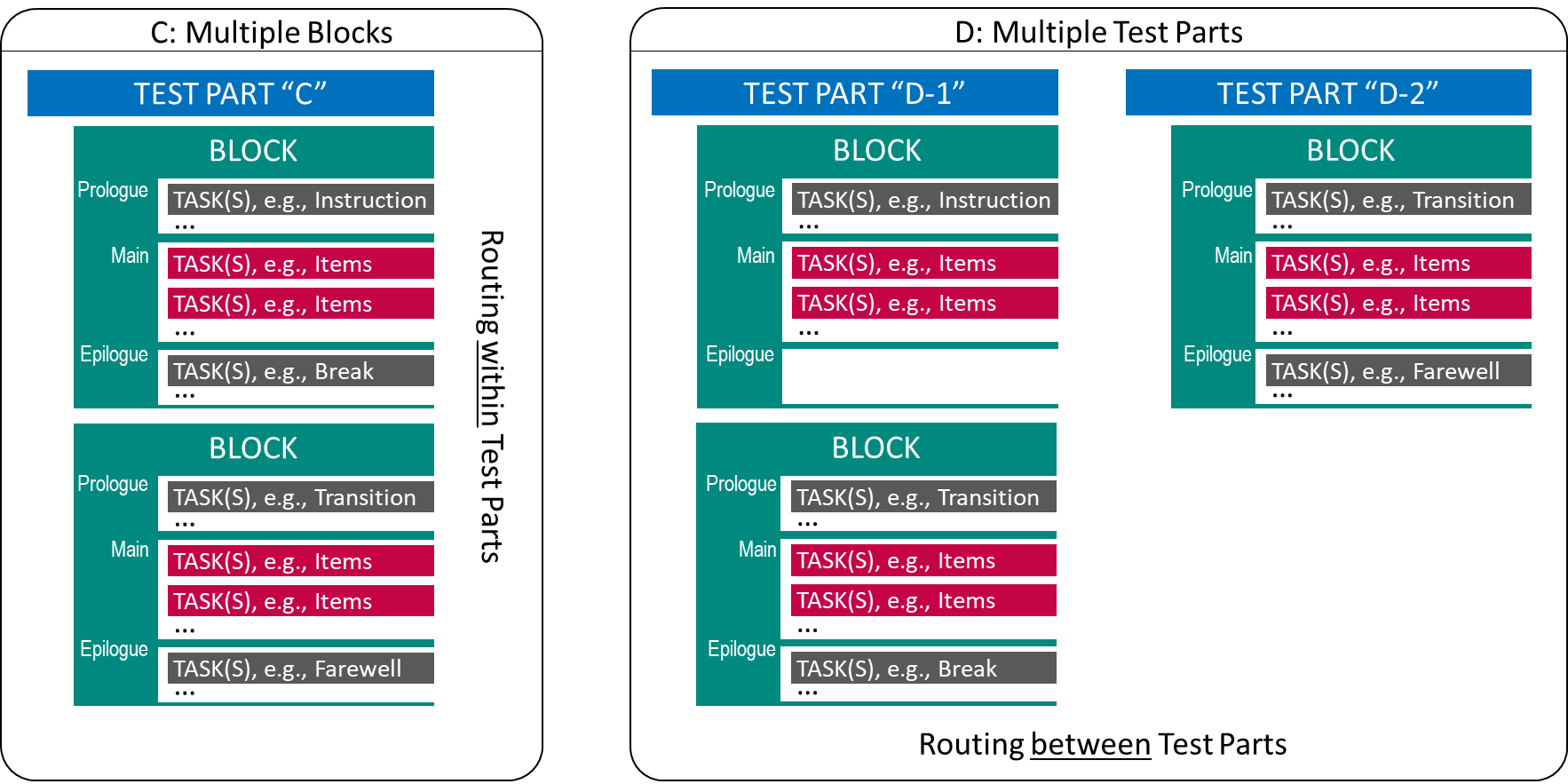
FIGURE 2.15: Fixed Form Testing with multiple Blocks or Parts.
The difference between Panel C (multiple Test Blocks within one Test Part) and Panel D (multiple Test Parts) in Figure 2.15 is only cosmetic, as long as Test Parts are also administered in a linear sequence. However, test deployment software might add the possibility to define the Routing between Test Parts differently than Routing within Test Parts. Moreover, as soon as different technologies come into play, Test Parts might use test content created with different tools (if supported by the test deployment software). In a typical educational assessment, a specific part (often administered at the end of a session) is dedicated to an additional questionnaire, that could serve as the content of the Block shown in the right part of Panel D in Figure 2.15.
2.7.2 Booklet Designs and Rotations
For various operational reasons, it may be necessary to define which Test Parts of a study definition are administered under which condition. In this way, for example, consent to test participation in different parts of an assessment can be incorporated, or the order of domains can be balanced or controlled.
Rotations of Test Content: One possibility to support such scenarios with a potential test delivery software is to allow conditional skipping (i.e., filtering) of Test Parts. A condition can be, for instance, a Preload-variable (i.e., a variable that contains information available about test-takers prior to an assessment; see section 7.5.3).
Figure 2.16 shows an example where a Test Part (“E-2”) is only administered if a hypothetical Preload-variable “Consent” has the value “true” (i.e., if, for example, parents have given their consent for a child to answer questions combined as Test Part “E-2”).
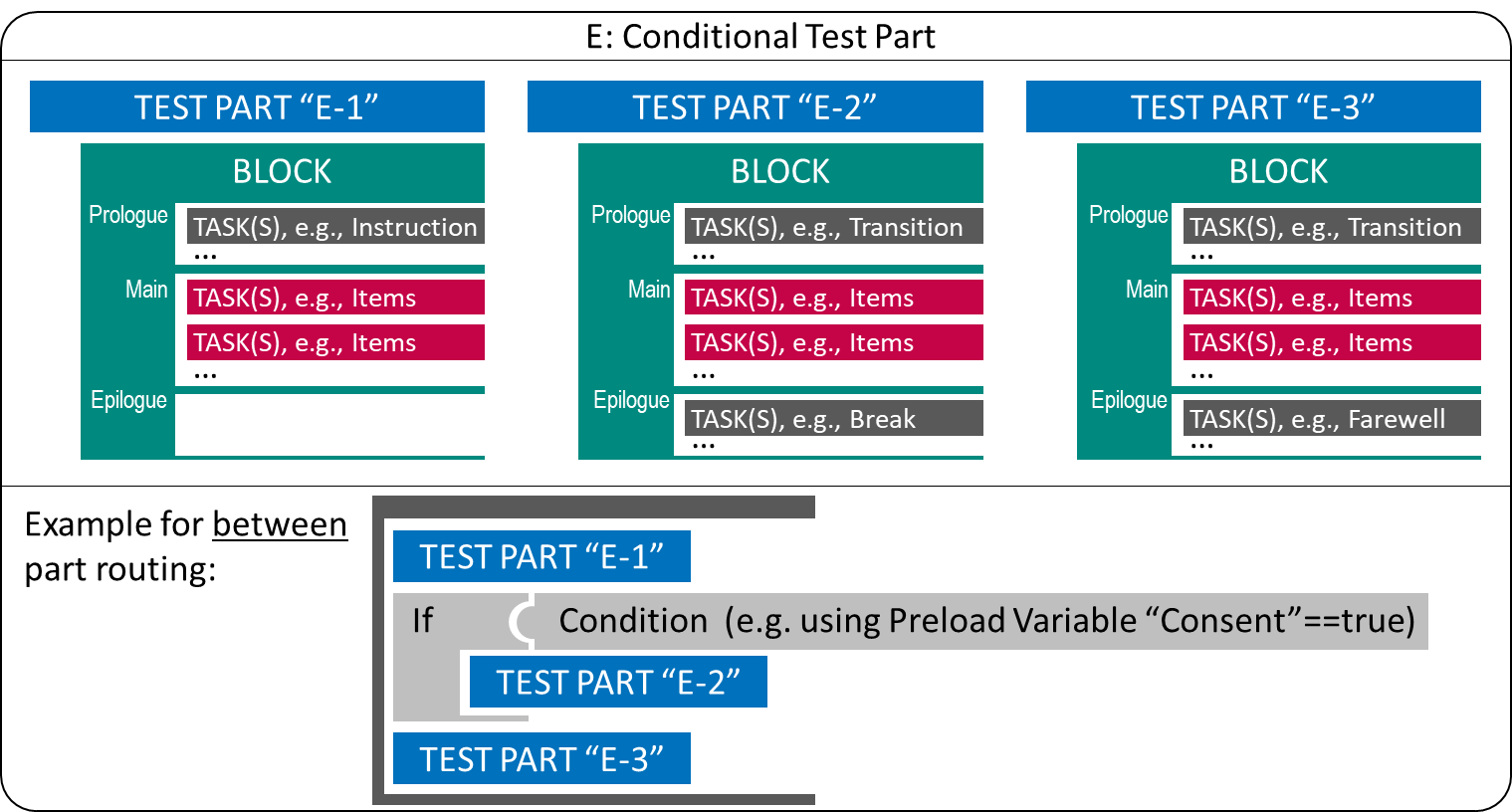
FIGURE 2.16: Conditional Test Part using between-part Routing.
Using multiple If-else-if-conditions (or a Switch-condition), multiple Rotations can be implemented, for instance used to make identical Test Parts usable in different sequences.
Booklet Designs: In large-scale assessments, multiple test forms or Booklets are also used to balance items across students, for instance, to ensure content coverage (e.g., A. Frey, Hartig, and Rupp 2009) or to link a huge amount of items (e.g., Yousfi and Böhme 2012). Defining individual Test Parts for items or combination of items (called, for instance, Clusters) can become cumbersome. Instead, test deployment software can make use of the underlying structure that provides rational for creating booklets, for instance, balancing the position of clusters in a permutation design (see Figure 2.17).
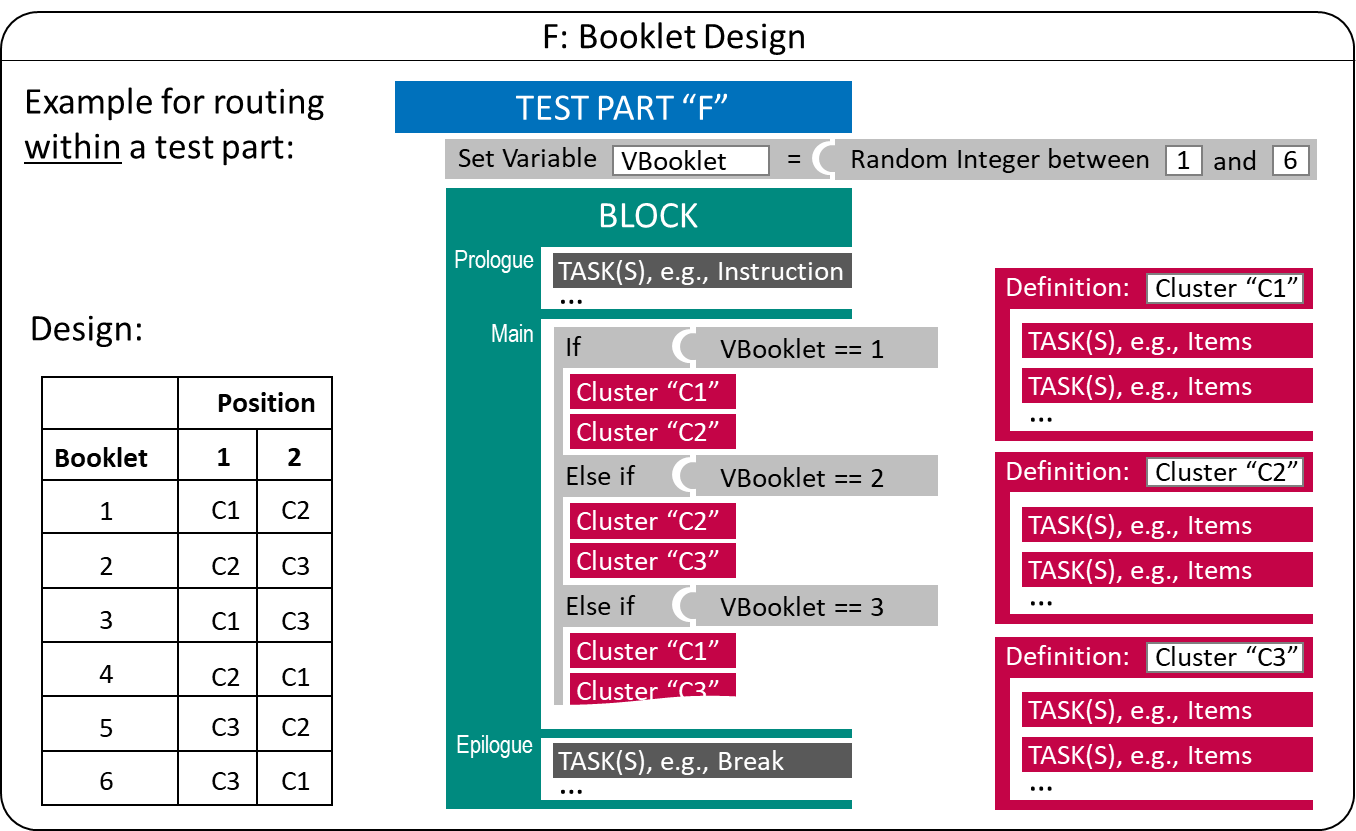
FIGURE 2.17: Example for a simple Booklet Design using within-part Routing.
The booklet design illustrated in Figure 2.17 has a random component (i.e., a random number is created during runtime for each test-taker and the value is is assigned to the variable "VBooklet") that is used to select the order in which two Clusters are administered. The clusters are created statically by listing tasks in a particular sequence in a separate definition that is re-used in the test assembly.
Booklets with Targeted Difficulty: One use case for multiple booklets is to align test difficulty or length with prior information about the test-takers. For this purpose, variable(s) used in condition(s) to select the Clusters or Tasks to be administered can contain information about test-taker, provided to the test deployment software as so called Preload-variables. If the Preload-variables contain information gathered in longitudinal designs in a previous assessment, a simple form of multi-stage testing can be implemented (Pohl 2013).
2.7.3 Multi-Stage Testing
If an (intermediate) scoring of at least some responses of previously administered items is feasible at runtime (i.e., if tasks contain items that can be automatically scored, see section 2.5.1), tailored testing becomes possible. A typical goal for multi-stage tests is to tailor the items’ difficulty to the test takers’ ability. Suppose there is no prior information that can be used as Preload-variables. In that case, this goal can be achieved by evaluating the test-taker’s capability after administering a first stet of tasks (a first stage in a test the combines multiple stages). As shown in Figure 2.18, as soon as a list of Tasks that constitute the first stage are administered, a variable "VStage1Score" can be computed that serves as the condition for a subsequent stage. In the most simplest form, a raw score is used as criterion, allowing to select the second stage by comparing the raw score of the first stage to a cut-off value.
Administration of Tasks within a Stage can allow test-takers to Navigate between units (see section 2.4.5), since the scoring is only done after the administration of all Tasks that create a Stage. In Figure 2.18 this is made explicit by illustrating the variable "VStage1ResultList", a list that contains all results gathered when administrating the Tasks of the first Stage.
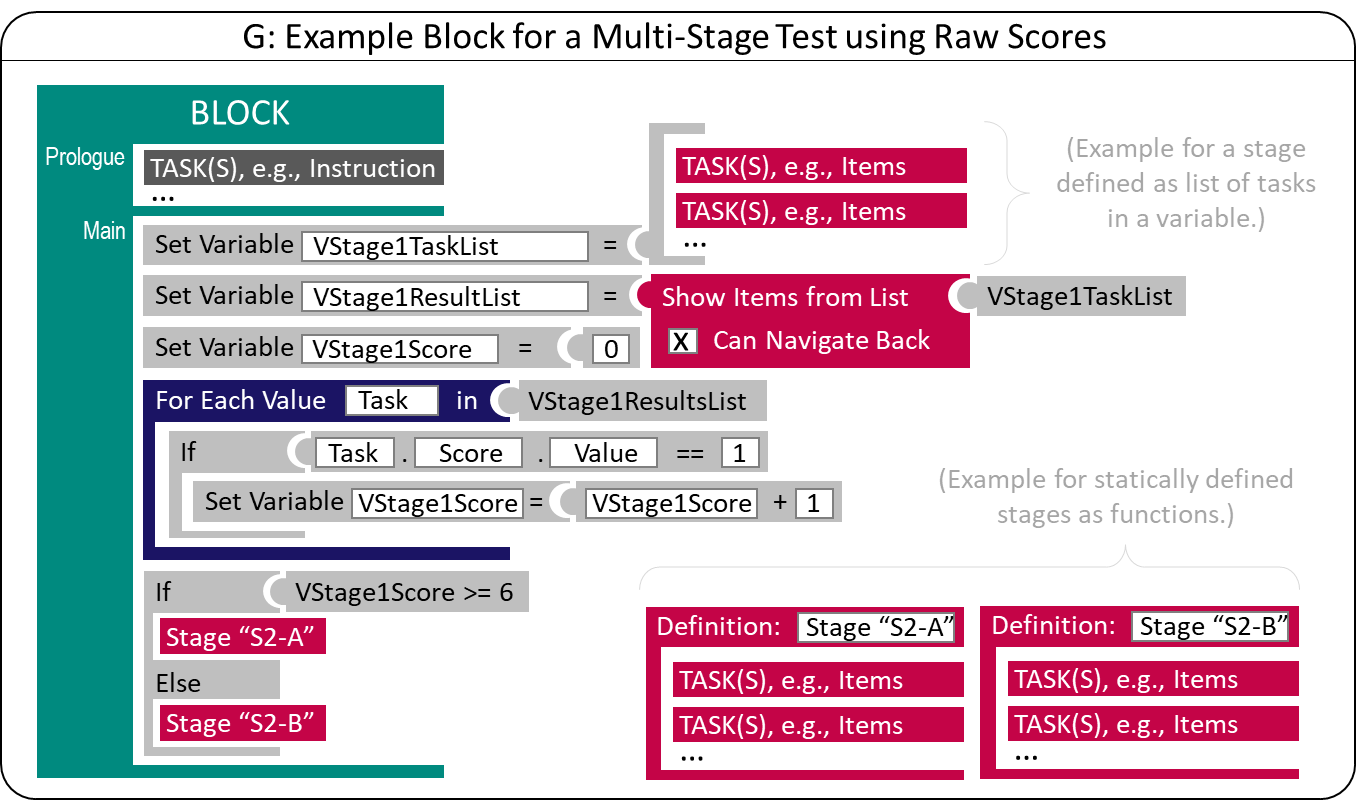
FIGURE 2.18: Basic Principle of Multi-Stage Testing
The tasks used for a particular stage26 can be defined statically in the test deployment software (see the definition for Stage "S2-A" and Stage "S2-B" in Figure 2.18) or stored in a variable (i.e., a list with at least one Task, see "VStage1TaskList"). Having the stage definition not static in the test specification (i.e., the configuration of the deployment software) allows for advanced approaches such as On-the-Fly Multistage Testing (e.g., Zheng and Chang 2015). A function that returns a list of tasks (selected from a larger pool of candidate items) based on the provisional estimation (temporary) or expected ability is required (see next section 2.7.4 about Computerized Adaptive Testing).
The list of results shown in Figure 2.18 can also be used in an IRT-based function for ability estimation (see section 2.5.5) if the raw score (e.g., the number of solved items) is not sufficient for routing between stages. An IRT ability estimate (i.e., the return value of an IRT-based function for ability estimation) is either a scalar representing a uni-dimensional ability estimate or a vector representing a multidimensional ability estimate.
2.7.4 Computerized Adaptive Testing
Computerized adaptive testing (CAT) is a method to increase measurement efficiency (see, for instance, Weiss 1982) based on Item Response Theory (IRT). Either single items or sets of items (Item Stages) are selected with respect to an item selection criterion such as the Maximum Fisher Information for dichotomous items (see van der Linden and Glas 2000 for an introduction), typically for a specific Provisional Ability Estimate. Adaptive testing can be illustrated as flow diagram as shown in Figure 2.19, based on a sequence of steps embedded into the CAT Loop.
FIGURE 2.19: Simplified Illustration of Computerized Adaptive Testing.
CAT Algorithms (i.e., algorithms used for adaptive tests) administer items until a particular Termination Criterion is reached. Termination Criteria are created based on the Test Length as the number of administered items (resulting in Fixed Length test) or the accuracy of the ability estimate (resulting in Variable Length test) or combinations. Hence, after initializing the adaptive test, a loop (see keyword While in Figure 2.20) is used to make sure the adaptive algorithm is terminated not before the termination criteria are met. In operational adaptive tests multiple criteria (including, for instance, that no suitable item was found in the Item Pool) can be used.
Depending on the select IRT model used to calibrate the items in the Item Pool (see section 2.5.4), a unidimensional (i.e., a scalar) or multidimensional (i.e., a vector) ability estimate is used as Start Value, as Provisional Ability Estimate and as the Final Ability Estimate. During the Initialization of an adaptive test, prior information can be used to adopt the Start Value (i.e., the ability estimate that is used to select the first item(s) of the adaptive test). Preload-variables can be used, for instance, to assign group-specific Start Values (see Figure 2.20 for an example).27

FIGURE 2.20: Illustration of Computerized Adaptive Test Initialization
Items are selected from an Item Pool (i.e., a list of Tasks with known Item Parameters, see section 2.5) and item selection algorithms can incorporate additional constraints (see section 2.7). For constraints management (see, for instance, Born and Frey 2017), additional parameter stored in an Item Pool can be required, for instance, for Exposure Control (e.g., Sympson-Hetter-Parameter, Hetter and Sympson 1997) and for Content Balancing (e.g., answer keys, see Linden and Diao 2011).
Item selection either results in one single item (Item-by-Item adaptive testing) or a list of items (Item Stages), similar to On-the-fly Multi-Stage Testing. As described above, a list of items (with at least on entry) can be used to store the selected items used for test administration (see "SelectedItems" in Figure 2.21).

FIGURE 2.21: Illustration of Computerized Adaptive Testing Loop
Navigation between Tasks of an Item Stage can be allowed since item selection only takes place after administering all Tasks. Scoring of all or selected administered items (see section 2.5.1) is required for the subsequent update of the ability estimation. Scoring can take place inside of the item or based on the list of result data (see "SelectedItemsResults" in Figure 2.21).
2.8 Log and Process Data

Computer-based assessments provide the opportunity to collect not only the final work product (i.e., raw responses and scored responses, see section 2.5.1) but also to allow the collection of so-called log data that origin from students’ interactions with the computer-based assessment platform (e.g., clicked buttons, selected radio buttons or checkboxes, entered text, mouse-moves, etc.) or internal system changes (e.g., timers). The examination of these log data from cognitive ability testing has gained increased attention (Goldhammer and Zehner 2017), for instance, in educational research, since the computer-based assessment was introduced in large-scale assessments (e.g., Greiff et al. 2016).
2.8.1 Basic Terminology
In the context of computer-based assessment, using log data is still a relatively new field of research. Different terms like stream data, log file data, event data, process data, and others are used (and sometimes mixed). In order to illustrate the meaning and use of log data for the theory-based construction of process indicators and to provide guidance concerning potential implementations in the CBA ItemBuilder, a conceptual clarification follows first.
Paradata: Additional information about the test-taking process and the data collection can be understood as part of the so-called paradata, commonly used in social science research (e.g., Kreuter 2013). Kroehne and Goldhammer (2018) summarizes categories of access-related, response-related and process-related paradata.
Response-related paradata include all user interactions (pointing device like mouse click or touch events, keyboard entries of hardware keyboards or soft keyboards) together with all state changes of components that have different states (components like checkboxes, radiobuttons etc. that can be selected and deselected) and internal states (like timers etc.)
Process-related paradata cover, for instance, information related to the navigation within assessment instruments (see section 2.4) as well as interactions not directly related to item responses
Additional assess-related paradata can occur when administering computer-based assessments. For example, this data can inform when an assessment is started, continued, or completed with what type of device.
Describing possible paradata with a taxonomy cannot cover all possible future applications of the additional information available in technology-based assessments. For a deeper look, it is worth considering the underlying nature and origin of this additional information, the emergence of which can be conceptualized in terms of events that create what is called Log Data.
Log Events: Log Data are generated and stored by assessment platforms as events, that inform about how a platform providing assessment material was used and how a provided platform changed (see section 1.6). For the data to be events, we can assume without further limitation that each event contains the following information:
- Time stamp: When did something take place?
- Event name: What has taken place?
The Time Stamp can represent an absolute date and time, or it can represent a relative time difference. The Event Name (or Event type) is only a first nominal distinction of different events. As described in section 1.6, log events in the context of assessments can be expected to contain the following additional information:
- Person identifier: Which test-taker can it be assigned to?
- Instrument identifier: Which part of an assessment can it be assigned to?
The assignment to a person is made by a reference (e.g., in the form of an identifier), and this personal reference must be taken into account in the context of using log data as research data (e.g., in the form of an ID exchange, see section 8.6). The reference to a part of the instrument can be established, for example, by an item identifier or a unit identifier or by describing the level at which a log event occurred (e.g., test-level).
- Event-specific attributes: What additional information describes what happened?
The Event Name describes various possible log events distinguished by an assessment platform. Each Event can provide specific further information, which in addition to the Event Name form the actual content of the log data. Depending on the event type, the event-specific attributes can be optional or required, and attributes can have a data type (e.g., String, Boolean, or some numeric type). If the information provided by the assessment platform with an event-specific attribute is not in atomic format (i.e., if it is not a single piece of information but a data structure, see Kroehne In Preperation for details), storing log data in rectangular data set files becomes more challenging (see section 2.8.4).
- Raw Log Events: From a technical perspective, events in digital environments like web browsers are required and used for programming and implementing digital (interactive) content, such as assessment instruments. Accordingly, a basic layer tries to connect at a low level to make those events available and usable for diagnostic purposes. The resulting log events not specific to any concrete task or assessment content are called Raw Log Events. Raw Log Events have event types that relate the captured information to the event’s origin (e.g., button click, mouse move, etc.). Raw log events are not necessarily schematically identical to the events of the used technological environment in which the (interactive) assessment content is implemented (such as, for instance, HTML5/JavaScript for browser-based content). However, raw log events are platform specific (i.e., different software implementations of identical content can provide different raw log events). Hence, the assessment software defines which raw log events are captured (and how).
- Contextualized Log Event: Based on the assessment content, a second kind of log event can be described: Events that inform about an event concerning a particular action or change in a concrete task or a particular item. These events can be called Contextualized Log Events, and instrument developers (i.e., item authors) need to define which particular action or internal change has which particular meaning. The event name (or event type) can encode the semantics of contextualized log events, and contextualized log events fit (as raw log events) into the concept of log events as described above.
ExternalPageFrames) can provide custom log-entries (Raw Log Events or Contextualized Log Events) via the API described in section 4.6.4.
Feature Extraction: Tagging or labeling selected Raw Log Events as Contextualized Log Events can be understood as an example of Feature Extraction (i.e., the derivation of Low-Level Features using the raw log events, see Kroehne and Goldhammer 2018). In this context, Contextualized Log Events are Actions (i.e.,Low-Level Features that occur at a point in time but do not have a time duration). More generally, Actions are contextualized information that can be extracted from the log data. So-called States (i.e., Low-Level Features that have a time duration) supplement the possible features that can be extracted from log events. As a rule, log events indicate the beginning and end of a States, while Actions represent specific Log Events that occur within States.
Process Indicators: Information about emotional, motivational, and cognitive processes during assessment processing may be contained in log data. Their interpretation in the context of assessments is guided by psychometric concepts such as validity (e.g., Goldhammer et al. 2021) and scientific principles such as reproducibility, replicability, and (independent) replication of empirical research.
Raw log events are platform-specific and are not suitable for defining indicators since if an assessment is re-implemented in a different technical platform, it cannot be assumed that the Raw Log Events will arise identically. Accordingly, the definition of process indicators that can become the subject of empirical validation is based on low-level features (Actions and States), where Actions also include Contextualized Log Events.
In this context, Process Indicators are aggregates of Low-Level Features (e.g., the number of occurrences of a particular Action or the aggregated time in a particular State), meaning values of person-level variables that can be derived from low-level features, and for whose interpretation theoretical arguments (e.g., in the sense of evidence identification) and empirical support can be collected. Psychometric models (e.g., measurement models) can be used, for instance, to investigate the within-person relationship of process indicators across different items or tasks and their relationship to outcome measures.
2.8.2 Item Designs and Interpretation of Log Data
In line with the terminology described in the previous section, Kroehne and Goldhammer (2018) describe a framework for analyzing log data. The core of this framework is the decomposition of the task processing into sections (called States), which can be theoretically described regarding an assessment framework.
The presentation of an assessment component (i.e., an item or unit, for example) always begins in a designated start state. Raw Log Events collected by an assessment platform can be used to mark the transition from one state to another state. As described above, Raw Log Events can also indicate specific Contextualized Log Events (i.e., Actions with a task-related interpretation). This way, two identical Raw Log Events can be interpreted differently depending on the current state (called Contextual Dependency of Log Events, see Kroehne and Goldhammer in Press).
Decomposition of Test-Taking Processes: The theoretical framework can also be used to describe item designs with respect to the interpretability of log data. For this purpose, it is helpful first to consider what creates States. According to Kroehne and Goldhammer (2018) the meaning of States is constituted by combining the displayed information (i.e., what is presented to test-takers on screen) with the possibilities to interact (i.e., what can test-taker do and how can test-taker interact with the content).
Suppose the presented information changes (i.e., a page change or a modification of the visible area of a scrollable page) or the opportunities change how the test-taker can interact with the assessment content. In that case, it may be helpful to describe the test-taking process using two different States. A log event (or events) can mark the transition between the old and new state (e.g., a page-change-event or scroll-event). If the interpretation of the two states differs meaningfully, then the interpretation of the involved log event(s) follows from the difference between the two states.
Log events can, for example, represent the selection of a response from predefined response options (i.e., events that can be categorized as answer-change-event). Suppose a State contains the view of an item stem, question, and the possibility to respond, for instance, by selecting a radio button. In that case, these answer-change-events can distinguish two states, BEFORE_RESPONDING and AFTER_FIRST_RESPONSE. While the assessment is ongoing, meaning while the item is on screen and the test-taker still has the opportunity to change the response, the state AFTER_FIRST_RESPONSE cannot be further decomposed into WHILE_RESPONDING (the time between the first and the last answer-change event) and AFTER_RESPONDING, as it is not yet decided whether the test-taker will select an answer only once (meaning, only one answer-change-event), or the test-taker will change to a different answer by clicking on different radio button. However, the situation will be different if log data from concluded assessments are analyzed. Either way, the interpretation of the state BEFORE_RESPONDING rests on the premise that the item design allows assigning this time component to one question. This is only possible with assumptions when multiple questions are presented in parallel on one screen.
Process Indicators for Item Analysis: Based on the decomposition of test-taking processes into individual sections (i.e., States), which are subdivided by log events, an in-depth item analysis can be performed, for example. An example of using frequency-based aggregates of low-level features (e.g., number of Actions meaning events tagged as answer-change events) and low-level features within states (e.g., number of visits of an item after selecting a final response), as well as time-based aggregates (e.g., total time after selecting the final response), can be found in Lahza, Smith, and Khosravi (2022).
States with Dedicated Meaning: Theory-driven created, interpretable process indicators are also possible if dedicated States can be crafted with a specific interpretation regarding the measured construct. An example of this idea can be found at Hahnel et al. (2019), based on making additional information necessary for solving a task of the task solution visible only after a test-taker interaction. The additional information about the source of a document is placed on a dialog page, and buttons that create log events need to be clicked to open and close the dialog page.
A similar concept underlies the analysis of navigation behavior in hypertext reading when relevant pages (i.e., States reconstructed based on navigation behavior, on which information essential for the task solution is presented) are distinguished from irrelevant page visits (see e.g. Naumann 2015).
2.8.3 Completeness of Log-Data
Which Raw Log Events are provided by an assessment platform depends on the respective programming, and Contextualized Log Events are each related to concrete item content. Hence, both forms are not suitable to describe whether the programming of a computer-based assessment provides all (relevant) log events. Kroehne and Goldhammer (2018), therefore, describe different completeness conditions.
Log Data versus Result Data: The starting point for differentiating different completeness conditions of log data is the review of the relation between log data and result data of a (computer-based) assessment. The result data contain for each item the raw responses (for instance, the text entered into text fields and the selection of choice elements such as radio buttons and checkboxes), and if implemented within the assessment platform, the scored item responses (see section 2.5.1). Although result data can be missing coded (see section 2.5.2) already when provided by the assessment software, we ignore missing value coding for the following explanation.
Response completeness: Suppose a result variable that contains the final selection of, for instance, a group of radio buttons (e.g., A, B and C). The value for this variable is an identifier for the finally selected radio button or a transformation of this identifier to a numeric value using a simple mapping (e.g., 1=A, 2=B, and 3=C). Log data of the intuitive type answer-change are generated each time the selection of the radio button group is changed. If A is selected first, followed by a selection of C, two answer-change log events are expected, one for the first selection (A) and one for the second selection (C). Taking both log events together in the correct order allows us to reconstruct the final selection and, thus, the value of the result variable (C or 3). Hence, if all answer-change events are collected, the result data can be re-constructed form the log data. If this is possible, all answer-change events are logged (whatever technique is used to collect the responses), and log data are called response complete. To achieve this property, answer-change events needs to be ordered by timestamp. However, we do not need real time measures, it is sufficient that the order of log events is maintained by the logging.
Progress-completeness: If the answer-change events can not only be sorted, but all answer changes are logged immediately with sufficient accuracy, then log data can also be Progress Complete. To check this property, it must be ensured that the result variables can be determined from the log events at any time (and not only after an assessment component, i.e., an item or a unit, has ended). This property can be easily illustrated through text input. If the changes in a text input field are only logged when the input focus changes, then Progress Completeness is not satisfied because the values of the result variables can be reconstructed from the answer-change events only at the times when the test-taker leaves the input field. To achieve Progress Completeness all text changes (e.g., in connection with the key-down or key-up-events) would have to be logged.
State‑completeness: The completeness conditions described so far are agnostic regarding the planned use of log data. This is different for the condition described as State Completeness. Consider a use case in which we want to replicate findings from a specific study that used a particular set of States (or specific Actions or Contextualized Log Events). To verify that this replication will be possible using the assessment software under consideration, State Completeness needs to be checked regarding this differentiation. For that purpose, all transitions between distinguished States need to be identified with available Raw Log Events. Note that the Raw Log Events used for the re-implementation can be different from the original implementation as long as all required transitions (as well as Actions and Contextualized Log Events) can be recognized from the log data with specific Raw Log Events that are provided by the new platform.
Replay‑completeness: Verifying log data with respect to State Completeness is especially helpful if a concrete set of States and Actions (or Contextualized Log Events) is known. If one wants to ensure that log data is as complete as possible so that all changes based on user interactions and internal state changes, such as timers, etc., are included in the log data, then Replay Completeness is helpful. Replay Completeness is fulfilled when a screencast (like a video)28 can be recreated from the collected log data. Figure 2.22 provides an example.
An understanding and objective analysis of the completeness of log data (i.e., what interactions and system state changes can be inferred from the log event data) is also crucial for making valid statements about Idle Times and for interpreting time differences in log data analyzed as time-stamped action sequences (e.g., Ulitzsch, He, and Pohl 2022).
2.8.4 Data Formats for Log Data
Log data collection often requires specific programming and presents additional requirements that must be specified, implemented, and tested (see, for instance, section 8.4 for details about Testing of CBA projects).
Even though based on the definition of log events described above (see section 2.8.1), the structure of the event data can be derived, the data of software developers in concrete assessment software tools do not necessarily have to be stored in log files in a structured way. Often log data is stored mixed with other data (including paradata and metadata), and functional requirements (regarding presenting assessment content and collecting final responses) might be prioritized for the assessment software in comparison to a transparent separation of different data forms.
For various reasons, data from an assessment platform may initially be stored in a preliminary (and proprietary) data format, and additional steps of data post-processing (see section 8.6 may be necessary to extract the Raw Log Event data (or Contextualized Log Events). The data formats for log event data described briefly below must therefore be generated from the data from the preliminary data formats used by particular assessment software. It does not matter whether the assessment software stores the data internally in a relational or document-based database or whether it is based on the generic markup language XML or the JSON serialization commonly used in web contexts.
Flat and Sparse Log Data Table: Starting from a long-format with one event per line, the storage of log data in the form of a one big Flat and Sparse Log Data Table (FSLDT) is possible (Kroehne In Preperation). As long as the minimal conditions described above (see section 2.8.1) are fulfilled (i.e., each log event is assigned to a person, has an event type or name, and a timestamp), the corresponding columns in the FSLDT are filled in for each line. Suppose many different event types that contain different required or optional event-specific data. In that case, the FSLDT contains many missing values and can become large and messy. Moreover, additional specifications are required for non-atomic event-specific data (i.e., to handle nesting, see Kroehne In Preperation).
Universal Log Format: Log data can be stored clearly and efficiently using simple relational database concepts. For this purpose, the data is stored in tables per event type. Each of these data tables thus contains fewer missing values, and the semantics and data types of the event-specific attributes (i.e., columns) can be defined and documented (see section 8.7). Missing values only occur for optional event-specific attributes, and additional specifications can be used to handle nested data types in the form of additional tables.
The individual tables per event type can be combined and sorted again based on the time stamps to create an FSLDT. The individual tables can be saved as data sets in the common data set formats (CSV, Stata, SPSS, …) and thus easily managed by research data centers since standard procedures (e.g., for the exchange of identifiers, see section 8.6) can also be applied.
eXtensible Event Stream (XES): Developed to achieve interoperability for archiving event logs data, the IEEE 1849-2016 XES Standard is the most attractive format for storing log data in a way that different tools can read. As described in Kroehne (In Preperation), the XES format combines information about the log data (i.e., how the data are stored) and the data, making this standard very flexible and valuable for log data from computer-based assessments. However, although the data are stored in XML format, researchers unfamiliar with the XES standard cannot read or verify the data without additional tools.
Learning Analytics: Log data gathered in assessment can also be described and stored using the concepts developed in the domain of learning analytics (for instance, the experience API statements, xAPI). The test-taker, required for log events after data preparation as person identifier corresponds to the actor in an xAPI statement. The event name (if necessary in combination with one or multiple event-specific attributes) can create a verb (e.g., clicked). The object is specified by the instrument identifier, and when necessary, further specified by event-specific attributes. Finally, context information of an xAPI statement can refer to access-related paradata (e.g., the location where an assessment takes place) or to metadata or linked data (such as the instructor of a course, in which an assessment is conducted).
Note that other standards (such as IMS Caliper and Hao, Shu, and von Davier 2015) exist that might be worse to consider.
2.8.5 Software Tools
The development of generic tools for analyzing log data from computer-based assessments is still in its infancy. Often, log data are only analyzed in a study-specific way, for example, by creating specific programs for analysis (cf. PIAAC Log Analyzer, Goldhammer, Hahnel, and Kroehne 2020).
LogFSM: A generic tool for analyzing log data based on algorithmic processing of log events (Raw Log Events or Contextualized Log Events) using finite-state machines is the R package LogFSM, which implements the framework for feature extraction suggested by Kroehne and Goldhammer (2018). Finite-State Machines (FSM, e.g., Alagar and Periyasamy 2011) are used, for instance, in the CBA ItemBuilder to implement dynamic interactive items (see section 4.4, and Rölke 2012; Neubert et al. 2015). Similar principles are also useful for the analysis of log file data (e.g., Kroehne and Goldhammer 2018).
Further R Packages: Additional R packages for analyzing log data include, for instance, LOGAN (Reis Costa and Leoncio 2019) / LOGANTree, ProcData (Tang et al. 2021), and TraMineR (Gabadinho et al. 2011).
2.9 Feedback
Computerized assessment allows for a variety of different forms of feedback. Feedback can relate to the answering process and the answers themselves.
2.9.1 Feedback during the Assessment
Different feedback forms can also be distinguished, either always displayed during the assessment or retrieved optionally. Some of the basic options are briefly described in this section.
Real-Time Feedback while Responding: Interactive items can be designed so that the cognitive operations for completing a task change as part of the response format. This type of feedback during test-taking is illustrated in the item in Figure 2.23 for an example matrices task. In this example, once the answer is chosen, it is already presented in the context of the stimulus, supporting verifying the submitted answer without explicitly providing feedback about task correctness.
Real-Time Feedback about Results: Closed response formats or automatically scored items allow explicit feedback about the results provided either immediately or delayed (Shute 2008). As discussed in van der Kleij et al. (2012), the operationalization of immediately (e.g., feedback given during the completion of an item) and delayed (e.g., feedback given directly after completion of all the items in the assessment) differs across research. Different types of feedback are investigated and used in practice and real-time performance feedback is considered (e.g., scaffolding feedback, Finn and Metcalfe 2010), in particular, attractive for formative assessments (DiCerbo, Lai, and Matthew 2020).
Feedback about (Remaining) Time: Especially when moderate time limits are used for larger test sections, it is helpful to integrate feedback about the remaining time into the items to make the information available to all test takers in a comparable (standardized) form.
The feedback can be implemented by displaying the remaining time (numerically) or by using a graphical visualization that visualizes the remaining time only roughly (in order not to create unnecessary time pressure).
Alternatively, as illustrated in the item in Figure 6.37, feedback on the remaining time can be provided, for example, at the item level by displaying a hint if an item still needs to be processed after a predefined time threshold.
Feedback about Task Progress: In addition to the remaining time, it is also helpful to provide feedback on overall test completion in computer-based assessments where progress cannot be inferred from the printed test booklet, as shown in Figure 2.25.
Feedback on Task Completion: The feedback about the processing status can also distinguish between visited pages and answered items. In that case, it is also possible to read how many tasks will still have to be processed from a progress display. A simple example is included in Figure 2.25. The graphical design can be more elaborate if multiple items are combined on individual pages.
Feedback about Navigation: As shown already in Figure 2.13, as soon as test-takers can not navigate back after leaving a section, unit, or page, a feedback dialogue or popup message is often used to inform the test-taker about the consequence of continuing.
Missing Value Feedback: The number of unfinished tasks can be displayed continuously or when leaving a unit. Suppose test takers cannot navigate back to a previous section. In that case, it makes sense to display a warning that can be designed differently for the case that all items have been answered (feedback about navigation) or that items still need to be answered (missing value feedback).
Rapid Guessing Feedback: Feedback about test-taking behavior, such as rapid guessing, can be provided to test-takers, either automatically [see, e.g., N.N.] or by test administrators (see, e.g., Wise, Kuhfeld, and Soland 2019).
Feedback on Consistency: Feedback about responding (too) quickly or unexpectedly fast is just one of many possibilities. If the software allows, for instance, person-fit measures can also be used to give feedback about inconsistent answers.
2.9.2 Feedback after the Assessment
Once data collection is completed for a single test-taker, there are multiple opportunities for further use of data for feedback purposes. Steps that can be relevant for creating feedback after an assessment include the scoring of responses (see section 2.5.1) and the ability estimation (using calibrated items, see sections 2.5.4 and 2.5.5).
Technical Platform for IRT-Methods: When an IRT model is used to model the measured construct, appropriate psychometric algorithms must be used for ability estimation, using pre-calibrated item parameters (i.e., the number of correct responses is not enough if the raw score is not a sufficient statistic). The necessary functions for ability estimation with various IRT models are freely available within software packages for data analysis (for instance, in the form of the R package TAM, Alexander Robitzsch, Kiefer, and Wu 2022). In order to use these functions also for operational computer-based assessments, the corresponding platform must be available (e.g., by using R with the help of the environments ShinyProxy, OpenCPU or the R package Plumbr), or the delivery environment must provide the required IRT functions.
Technical Platform for Report Generation: A technical solution for the automatic creation of feedback is also necessary to create texts and, if necessary, graphics and combine them into HTML, PDF, or other text documents [e.g., R and the package kntir, Xie (2015); see section 7.3.5 for an example].
Technical Inclusion of Process Indicators: In addition to outcome variables, process indicators representing aggregations of Low-Level Features that can be extracted from log data using algorithms (see section 2.8) can be helpful in generating feedback. A technical platform is also required for this necessary analysis of the log data, in which, for example, the R package LogFSM (see section 2.8.5) can be integrated.
2.10 Item and Test Security

Computer-based testing is also connected in different ways with the concept of item and test security.
2.10.1 Protection of Items and Tests
Test security is first of all related to the protection of item content, of particular importance for high-stake assessments or for low-stakes assessments that aim to measure trends by using so-called link items. The core idea is that test instruments should only be accessible to a limited group of users to protect item contents from becoming known.
2.10.2 Secure Test Deployment
Whether and in what way item contents can be made known depends mainly on the type of test delivery. If, for example, a proctor is present on-site during a test session and the test is carried out in a so-called kiosk mode (see section 7.2.3), then the proctor and the software can help to manage the possibility of uncontrolled dissemination of item content.
From a diagnostic perspective, test security also has a second meaning: An assessment platform should implement a certain degree of restrictions so that the assessment can be carried out with as little disruption as possible. Since a certain degree is difficult to verify from an IT perspective, we work with the following operational definition of operational test security of assessments in terms of usability for diagnostic purposes:
The usability of computer-based assessments and the protection of items and tests are related, as both aim at restricting the possibilities of how the test-takers can interact with the test delivery while answering items and working on assigned tasks. The following examples illustrate for web-based deployments how a computer-based assessment can be challenged regarding the usability (and related to test security):
- Accidental closing of the entire browser can interrupt the assessment or result in losing data.
- Navigation using browser Back-, and Forward- buttons (instead of the buttons within the assessment content) might interrupt the assessment.
- Drag and drop operations on content that requires scrolling to be completely visible can occur unintendedly, for instance, if test-taker can reduce the size of a browser window.
- The attempt to open an assessment in a second window or tab can lead to unwanted interruptions or, in the worst case, inconsistencies in the data.
Thus, the question of the delivery of computer-based assessments can have a significant effect on the validity of measurements. Collecting log data, for instance, for so-called off-task behavior, can help identify and ultimately quantify the problem. However, interpreting scores at the individual level may be challenging or, analogous to disengaged response behavior and rapid guessing responses, impossible.
2.11 Design Principles of the CBA ItemBuilder

2.11.1 Content Experts as Item Developers
Creating good assessment items depends primarily on creating task contexts in which understanding can be applied and, where appropriate, knowledge can be demonstrated. As general as the concepts of computer-based testing and psychometric assessments are, as specific are the application areas and domains in which diagnostic questions are to be answered. The CBA ItemBuilder is therefore designed in such a way that content experts can use the software to create, test, and ultimately use items for computer-based assessments. The technical platform should support a wide range of possibilities of more innovative, technology-enhanced item formats, which is why the CBA ItemBuilder goes beyond the simple, although standardized item formats of IMS QTI and allows the design of multi-page interactive items.
2.11.2 Model-based Representation
The CBA ItemBuilder uses a component model to enable the graphical design of assessment contents. Starting from individual pages, the position of elements and their properties are defined with the help of a graphical editor. In the current version of the CBA ItemBuilder, this graphical editor is a program that can be installed on the computer (see section 1.1). With this program the abstract component model becomes the basis for the creation of assessment content. The visual part of the component model comprises pages (of different page type, see section 3.4), and the graphical Page Editor allows to add components from the so-called Palette to the pages. The components have various properties, such as the position (in pixels X and Y), the size (in pixel Width and Height) and many more (depending on the type of a particular component). The component model is stored within the item definition (in so-called Project Files) and used to generate source code (or a configuration file that can be used with a particular piece of software, called TaskPlayer API) that is used to use CBA ItemBuilder content in assessments.
2.11.3 Separation of Layout and Logic
The model-based representation of the assessment contents (using the component model as describe above), as implemented in the CBA ItemBuilder, is also the basis for a possible long-term archiving strategy of computer-based tests (see section 8.7.3). The basic idea here is that the runetime code can be updated from the model if a newer version of the CBA ItemBuilder can open project files of previous versions (see 3.2.1).
2.11.4 Containers and Nesting
Containers define which components can be added as child elements (i.e., only components of a particular type can be nested within containers of a particular type). Moreover, using the concept of containers, the order in which components are displayed (the so-called Z-Order, the sequence in which components are rendered on top of each other if they overlap) is defined for pages created with the CBA ItemBuilder. Containers are always rendered below their child elements. If a component is a container, the Z-Order of its nested components is defined by the order of the components within the container (see section 6.8.5 for details on overlapping components). Hence, the order in which components are added (i.e., the order within the Component Edit view) defines the order in which components are displayed on top of each other during runtime (i.e., in the Preview and when assessment components created with the CBA ItemBuilder are used in assessments).