2.7 (Automated) Test Assembly

When more items are available than can or should be completed by a test-taker, the term Test Assembly is used to describe the psychometric process of combining items to test Booklets or Rotations. The test assembly process usually requires items with known item parameters (see section 2.5.4) and can be performed manually or automatically (van der Linen 2006).
The research literature on automated test composition provides insight into criteria that are considered when assembling tests. The primary criterion is typically provided by item response theory, i.e., the selection of items to optimize the measurement by taking already available information about the anticipated test-takers (for instance, the expected ability distribution) into account.
Constraints: Approaches that formalize the test assembly (e.g., Diao and van der Linden 2011) can also incorporate additional criteria (i.e., constraints for the test assembly when conduced, for instance, in R, see Becker et al. 2021), such as:
- Content: Content areas or domains of requirements, defined as test specification in relation to an underlying assessment framework (i.e., the test blueprint)
- Response Format: Response format or number of response alternatives, or the position of the correct responses
- Item Position: Balancing the position of items or keeping the position of certain items constant (e.g. link items)
- Response Time: Expected time to solve the item (can be used to assemble tests that with comparable time limits)
Constraints can be considered in test composition to make different individual tests comparable or to balance and account for item properties at a sample or population level. Moreover, constraints might also be used to achieve further operational goals, such as the interpretability of adaptive tests at the group level for formative assessment purposes (e.g., Bengs, Kroehne, and Brefeld 2021).
2.7.1 Fixed Form Testing
Assessments with a fixed set of items can be seen as the typical use case for test deployments, either in the preparation of IRT-based applications of tailored testing (i.e., to collect data for item calibrations) or as the final output of test development. As shown in Panel A of Figure 2.14, a fixed form testing requires the administration of assessment components as linear sequence.

FIGURE 2.14: Fixed Form Testing with linear sequence of Tasks
Criteria for item selection, optionally taking into account constraints, is reflected in the selection of Tasks that are included in the linear sequence.
A first differentiation of the structure also of Fixed Form test assemblies (see Panel B in Figure 2.14) concerns the distinction in assessment components which are administered BEFORE the actual tasks (Prologue), the tasks themselves (Main), and the assessment components which are administered AFTER the main tasks (Epilogue). The subdivision made can be helpful if, for example, a time limit is required for a part of the assessment components (Main),25 but the time measurement does not begin until the instruction is completed (Prologue) and a uniform test-taker enactment is to be implemented (Epilogue).
Test designs using Fixed Form Testing can also incorporate multiple tests, domains or groups of Tasks as shown in Figure 2.15, by repeating multiple Test Blocks.
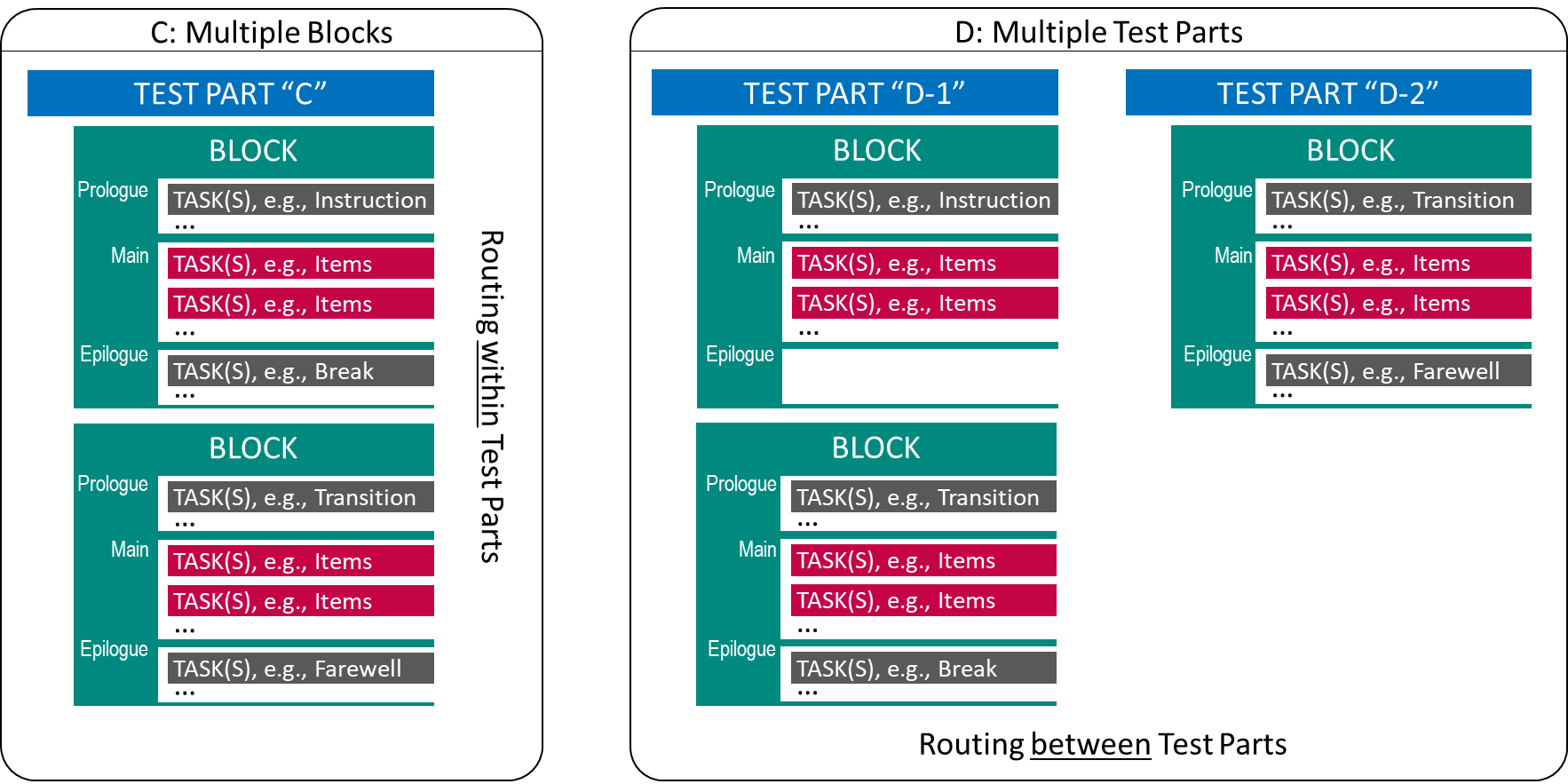
FIGURE 2.15: Fixed Form Testing with multiple Blocks or Parts.
The difference between Panel C (multiple Test Blocks within one Test Part) and Panel D (multiple Test Parts) in Figure 2.15 is only cosmetic, as long as Test Parts are also administered in a linear sequence. However, test deployment software might add the possibility to define the Routing between Test Parts differently than Routing within Test Parts. Moreover, as soon as different technologies come into play, Test Parts might use test content created with different tools (if supported by the test deployment software). In a typical educational assessment, a specific part (often administered at the end of a session) is dedicated to an additional questionnaire, that could serve as the content of the Block shown in the right part of Panel D in Figure 2.15.
2.7.2 Booklet Designs and Rotations
For various operational reasons, it may be necessary to define which Test Parts of a study definition are administered under which condition. In this way, for example, consent to test participation in different parts of an assessment can be incorporated, or the order of domains can be balanced or controlled.
Rotations of Test Content: One possibility to support such scenarios with a potential test delivery software is to allow conditional skipping (i.e., filtering) of Test Parts. A condition can be, for instance, a Preload-variable (i.e., a variable that contains information available about test-takers prior to an assessment; see section 7.5.3).
Figure 2.16 shows an example where a Test Part (“E-2”) is only administered if a hypothetical Preload-variable “Consent” has the value “true” (i.e., if, for example, parents have given their consent for a child to answer questions combined as Test Part “E-2”).
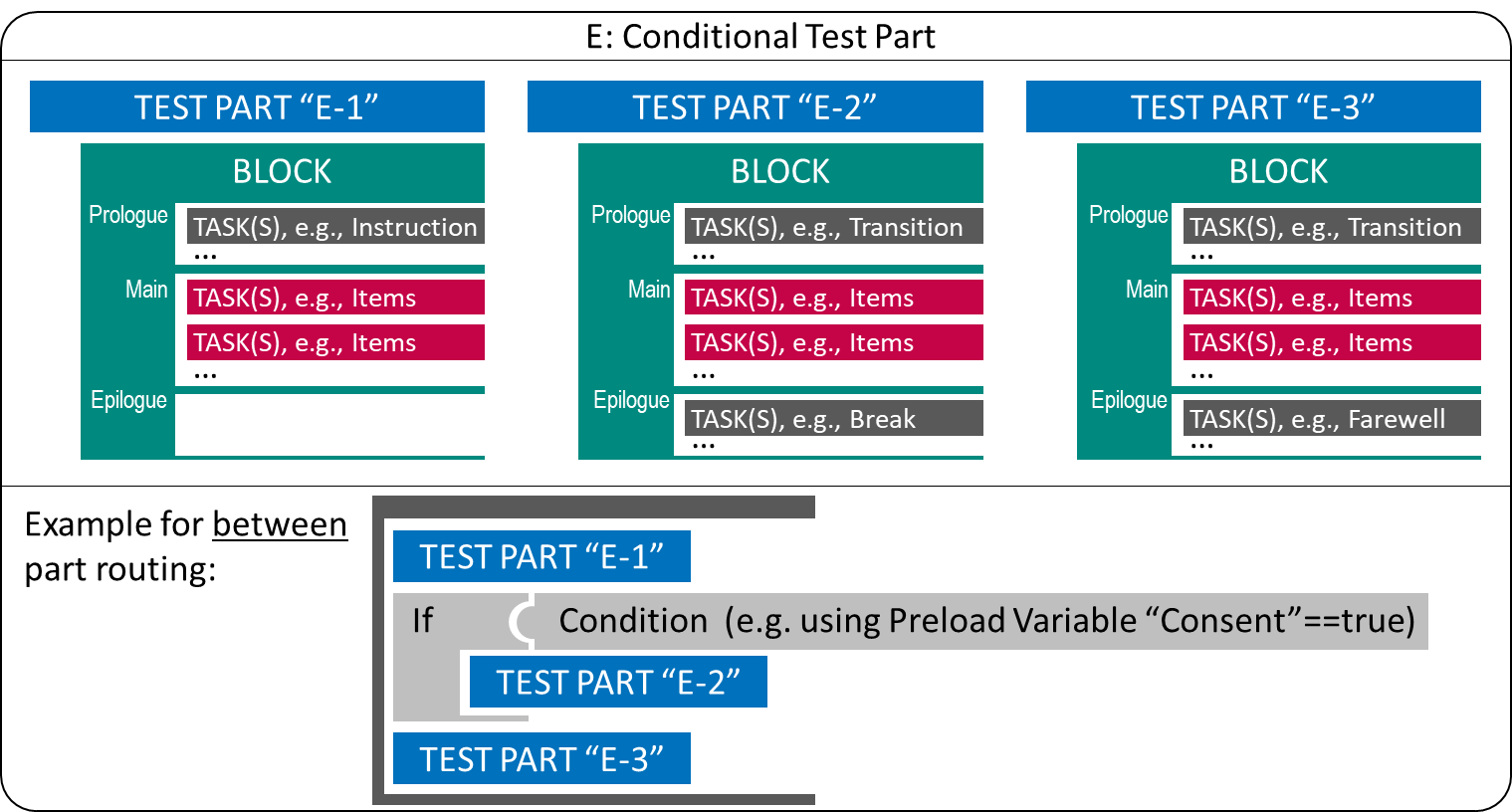
FIGURE 2.16: Conditional Test Part using between-part Routing.
Using multiple If-else-if-conditions (or a Switch-condition), multiple Rotations can be implemented, for instance used to make identical Test Parts usable in different sequences.
Booklet Designs: In large-scale assessments, multiple test forms or Booklets are also used to balance items across students, for instance, to ensure content coverage (e.g., A. Frey, Hartig, and Rupp 2009) or to link a huge amount of items (e.g., Yousfi and Böhme 2012). Defining individual Test Parts for items or combination of items (called, for instance, Clusters) can become cumbersome. Instead, test deployment software can make use of the underlying structure that provides rational for creating booklets, for instance, balancing the position of clusters in a permutation design (see Figure 2.17).
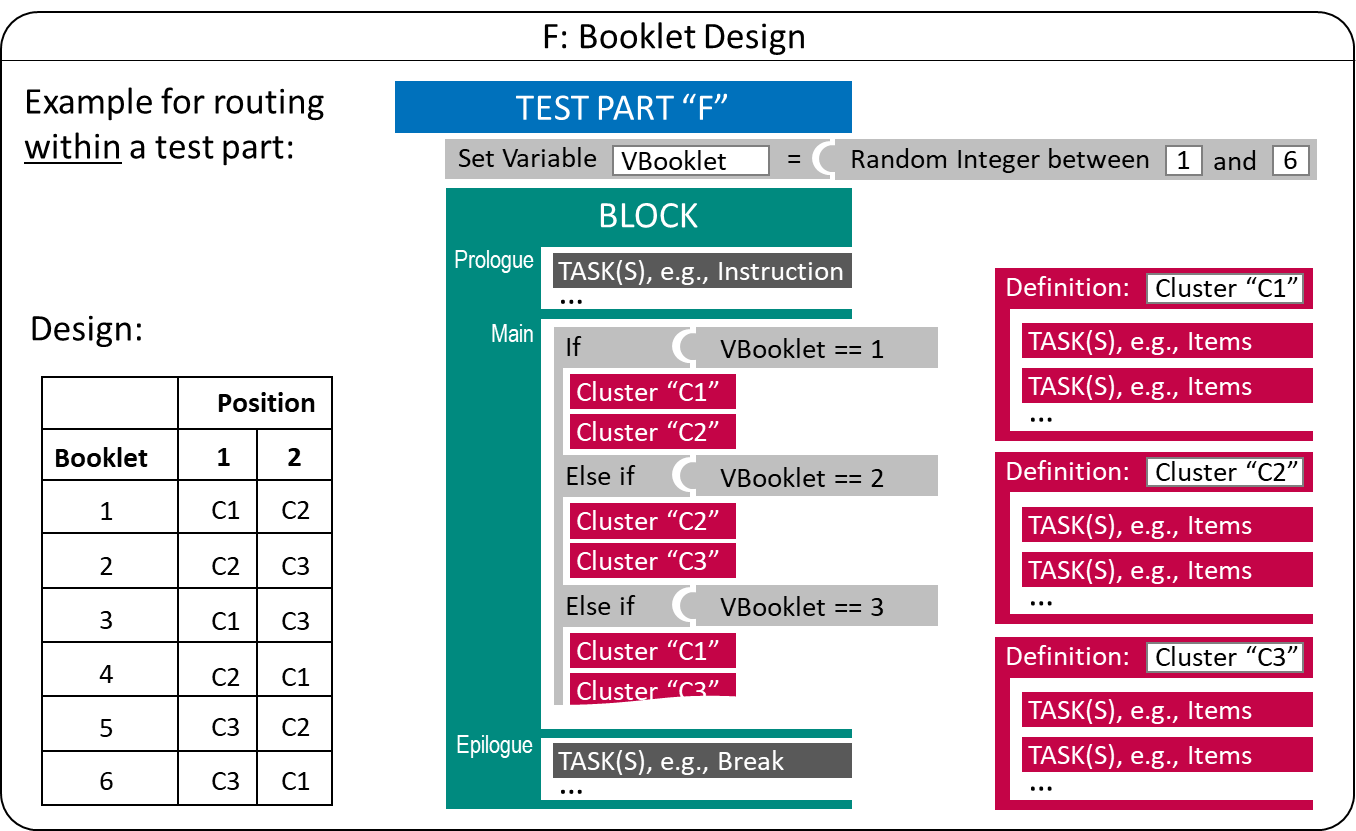
FIGURE 2.17: Example for a simple Booklet Design using within-part Routing.
The booklet design illustrated in Figure 2.17 has a random component (i.e., a random number is created during runtime for each test-taker and the value is is assigned to the variable "VBooklet") that is used to select the order in which two Clusters are administered. The clusters are created statically by listing tasks in a particular sequence in a separate definition that is re-used in the test assembly.
Booklets with Targeted Difficulty: One use case for multiple booklets is to align test difficulty or length with prior information about the test-takers. For this purpose, variable(s) used in condition(s) to select the Clusters or Tasks to be administered can contain information about test-taker, provided to the test deployment software as so called Preload-variables. If the Preload-variables contain information gathered in longitudinal designs in a previous assessment, a simple form of multi-stage testing can be implemented (Pohl 2013).
2.7.3 Multi-Stage Testing
If an (intermediate) scoring of at least some responses of previously administered items is feasible at runtime (i.e., if tasks contain items that can be automatically scored, see section 2.5.1), tailored testing becomes possible. A typical goal for multi-stage tests is to tailor the items’ difficulty to the test takers’ ability. Suppose there is no prior information that can be used as Preload-variables. In that case, this goal can be achieved by evaluating the test-taker’s capability after administering a first stet of tasks (a first stage in a test the combines multiple stages). As shown in Figure 2.18, as soon as a list of Tasks that constitute the first stage are administered, a variable "VStage1Score" can be computed that serves as the condition for a subsequent stage. In the most simplest form, a raw score is used as criterion, allowing to select the second stage by comparing the raw score of the first stage to a cut-off value.
Administration of Tasks within a Stage can allow test-takers to Navigate between units (see section 2.4.5), since the scoring is only done after the administration of all Tasks that create a Stage. In Figure 2.18 this is made explicit by illustrating the variable "VStage1ResultList", a list that contains all results gathered when administrating the Tasks of the first Stage.
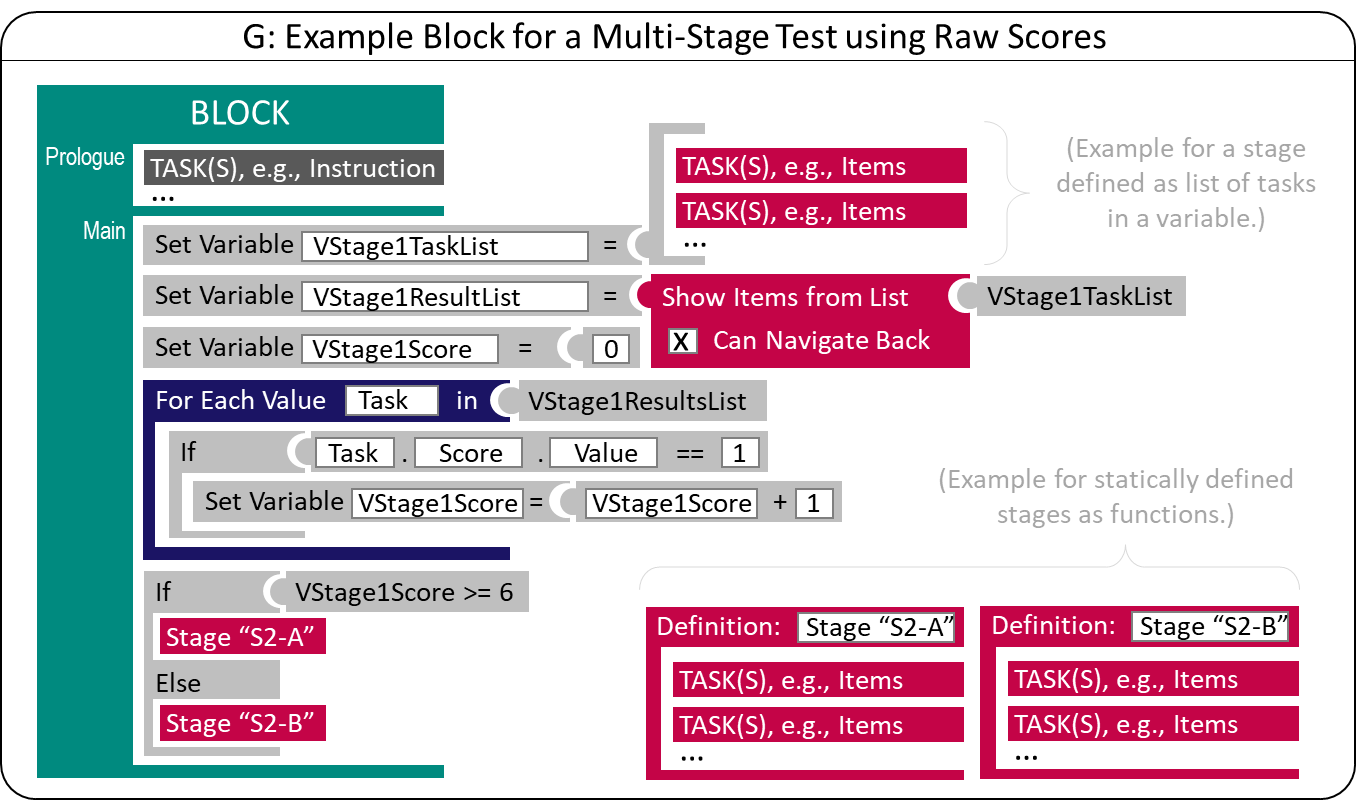
FIGURE 2.18: Basic Principle of Multi-Stage Testing
The tasks used for a particular stage26 can be defined statically in the test deployment software (see the definition for Stage "S2-A" and Stage "S2-B" in Figure 2.18) or stored in a variable (i.e., a list with at least one Task, see "VStage1TaskList"). Having the stage definition not static in the test specification (i.e., the configuration of the deployment software) allows for advanced approaches such as On-the-Fly Multistage Testing (e.g., Zheng and Chang 2015). A function that returns a list of tasks (selected from a larger pool of candidate items) based on the provisional estimation (temporary) or expected ability is required (see next section 2.7.4 about Computerized Adaptive Testing).
The list of results shown in Figure 2.18 can also be used in an IRT-based function for ability estimation (see section 2.5.5) if the raw score (e.g., the number of solved items) is not sufficient for routing between stages. An IRT ability estimate (i.e., the return value of an IRT-based function for ability estimation) is either a scalar representing a uni-dimensional ability estimate or a vector representing a multidimensional ability estimate.
2.7.4 Computerized Adaptive Testing
Computerized adaptive testing (CAT) is a method to increase measurement efficiency (see, for instance, Weiss 1982) based on Item Response Theory (IRT). Either single items or sets of items (Item Stages) are selected with respect to an item selection criterion such as the Maximum Fisher Information for dichotomous items (see van der Linden and Glas 2000 for an introduction), typically for a specific Provisional Ability Estimate. Adaptive testing can be illustrated as flow diagram as shown in Figure 2.19, based on a sequence of steps embedded into the CAT Loop.
FIGURE 2.19: Simplified Illustration of Computerized Adaptive Testing.
CAT Algorithms (i.e., algorithms used for adaptive tests) administer items until a particular Termination Criterion is reached. Termination Criteria are created based on the Test Length as the number of administered items (resulting in Fixed Length test) or the accuracy of the ability estimate (resulting in Variable Length test) or combinations. Hence, after initializing the adaptive test, a loop (see keyword While in Figure 2.20) is used to make sure the adaptive algorithm is terminated not before the termination criteria are met. In operational adaptive tests multiple criteria (including, for instance, that no suitable item was found in the Item Pool) can be used.
Depending on the select IRT model used to calibrate the items in the Item Pool (see section 2.5.4), a unidimensional (i.e., a scalar) or multidimensional (i.e., a vector) ability estimate is used as Start Value, as Provisional Ability Estimate and as the Final Ability Estimate. During the Initialization of an adaptive test, prior information can be used to adopt the Start Value (i.e., the ability estimate that is used to select the first item(s) of the adaptive test). Preload-variables can be used, for instance, to assign group-specific Start Values (see Figure 2.20 for an example).27

FIGURE 2.20: Illustration of Computerized Adaptive Test Initialization
Items are selected from an Item Pool (i.e., a list of Tasks with known Item Parameters, see section 2.5) and item selection algorithms can incorporate additional constraints (see section 2.7). For constraints management (see, for instance, Born and Frey 2017), additional parameter stored in an Item Pool can be required, for instance, for Exposure Control (e.g., Sympson-Hetter-Parameter, Hetter and Sympson 1997) and for Content Balancing (e.g., answer keys, see Linden and Diao 2011).
Item selection either results in one single item (Item-by-Item adaptive testing) or a list of items (Item Stages), similar to On-the-fly Multi-Stage Testing. As described above, a list of items (with at least on entry) can be used to store the selected items used for test administration (see "SelectedItems" in Figure 2.21).

FIGURE 2.21: Illustration of Computerized Adaptive Testing Loop
Navigation between Tasks of an Item Stage can be allowed since item selection only takes place after administering all Tasks. Scoring of all or selected administered items (see section 2.5.1) is required for the subsequent update of the ability estimation. Scoring can take place inside of the item or based on the list of result data (see "SelectedItemsResults" in Figure 2.21).
References
While time limits within assessment components created with the CBA ItemBuilder can be defined directly with Timed Events using the Finite-State Machine as part of item implementation (see section 4.4.3, time limits that are to work across different Tasks must be implemented with the test deployment software (see section 7.2.8).↩︎
The QTI 3.0 Specification refers to a list or batch of one or more items from the Item Pool as Item Stage.↩︎
The general structure of information used to initialize CAT algorithms is described, for instance in the QTI CAT Specification using key-value pairs.↩︎